
CNN简述与应用
*一、来源与背景*
在图像处理领域,cnn出现之前主要存在两个问题:
*1. 需要处理的数据量太大*
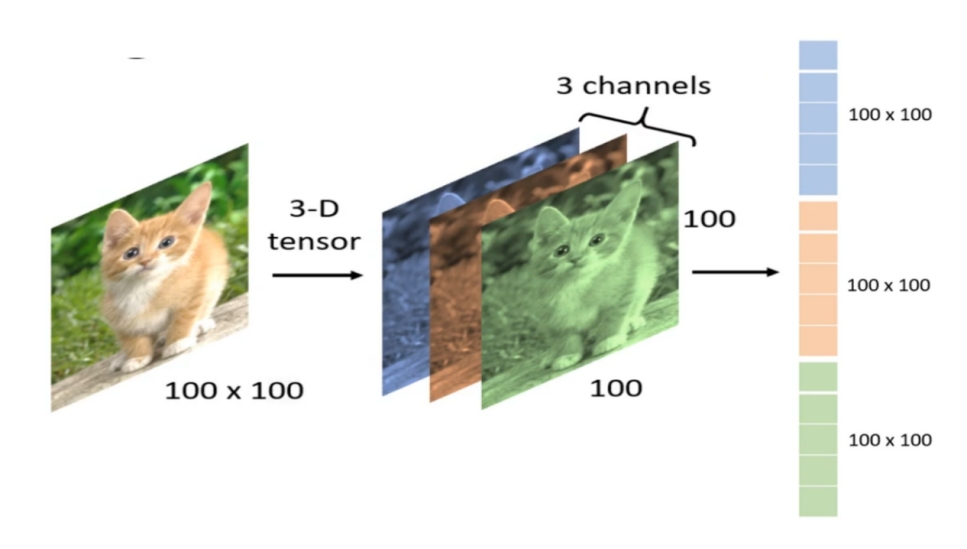
图像是由每个带有颜色的像素构成的,且每个像素都有RGB(可简单理解为光学三原色:红、绿、蓝)3个参数来表示颜色信息。
假如现在需要处理一张100100像素的图片,就需要处理100100*3=30,000个参数。
 *2. 弱化局部特征*
*2. 弱化局部特征*
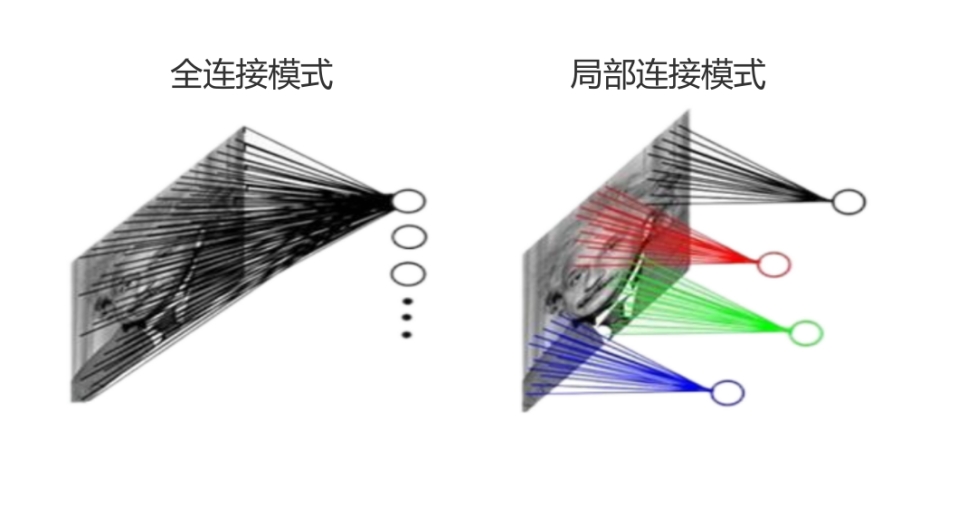
以往的全连接模式会对整张图片进行识别,无法有效提取图片中的细节特征,按照人眼的视觉信息识别方法,我们更会根据某些细节信息进行组合,从而识别物体,而不是通过整个画面进行识别,例如全连接神经网络可能更认为这是乌鸦而循环神经网络会认为是猫。



为此产生了CNN,通过将复杂问题简化和保留图像特征就较为完美地解决图像识别上的一些问题。
*二、CNN的发展*
*1. AlexNet*
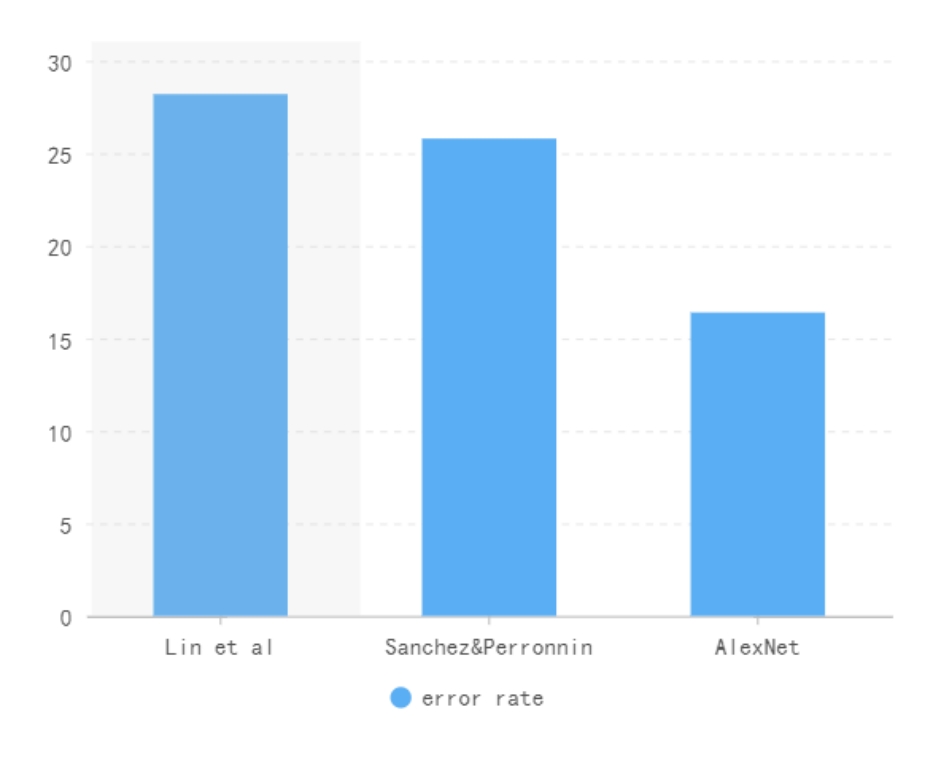
2012年,AlexNet的出现标志着神经网络的复苏和深度学习的崛起。在imageNet2012的图片分类任务上,AlexNet以15.3%的错误率登顶,而且以高出第二名十几个百分点的差距远超所有其他参与者。
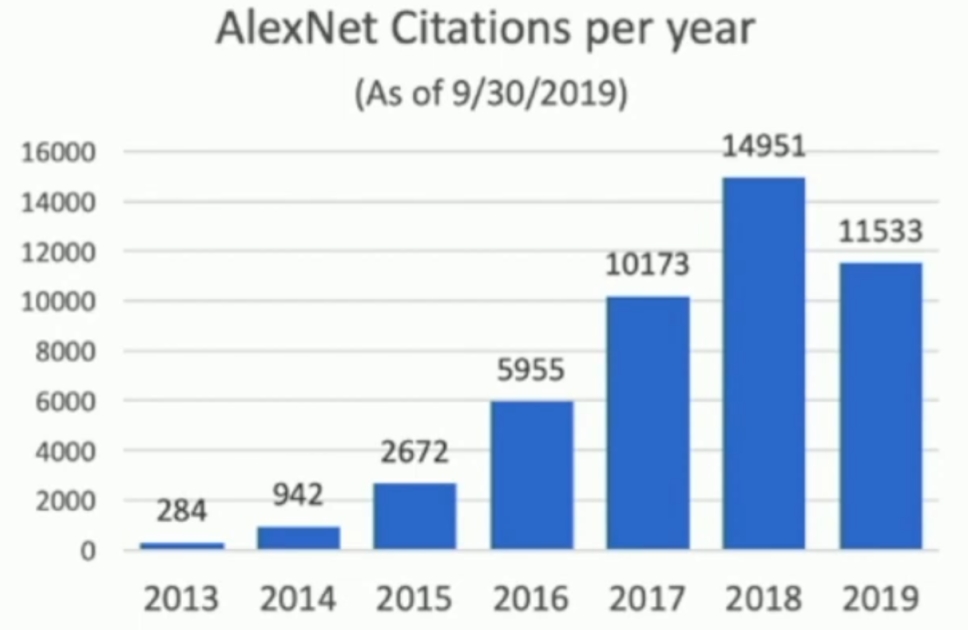
自从AlexNet发布后,该论文的引用量也在随后的几年中逐年上升,可见其模型对神经网络和深度学习的发展有着十分深远的影响。
同时AlexNet的模型架构也为后续的CNN模型架构建立奠定了基础,虽然具体参数和模型层数都发生了一定变化,但在逻辑结构和方法上,AlexNet都提供了一定的参考性意见。
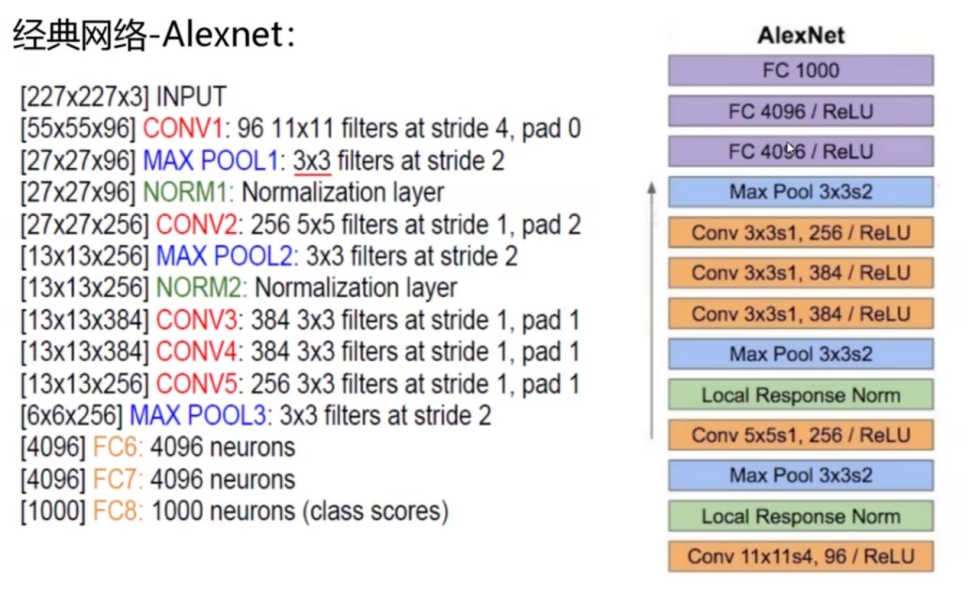
2. *CNN网络结构*
CNN是一种人工神经网络,CNN的结构可以分为3层:
卷积层(Convolutional Layer) - 主要作用是提取特征。
池化层(Max Pooling Layer) - 主要作用是下采样(downsampling),却不会损坏识别结果。
全连接层(Fully Connected Layer) - 主要作用是分类。
例如拿人类识别物品做类比,人类识别一张图片内容是小鸟时,首先会判断鸟的嘴是尖的,全身有羽毛和翅膀,有尾巴。然后通过这些联系起来判断这是一只鸟。而CNN的原理也类似,通过卷积层来查找特征,然后通过全连接层来做分类判断这是一只鸟,而池化层则是为了让训练的参数更少,在保持采样不变的情况下,忽略掉一些信息。
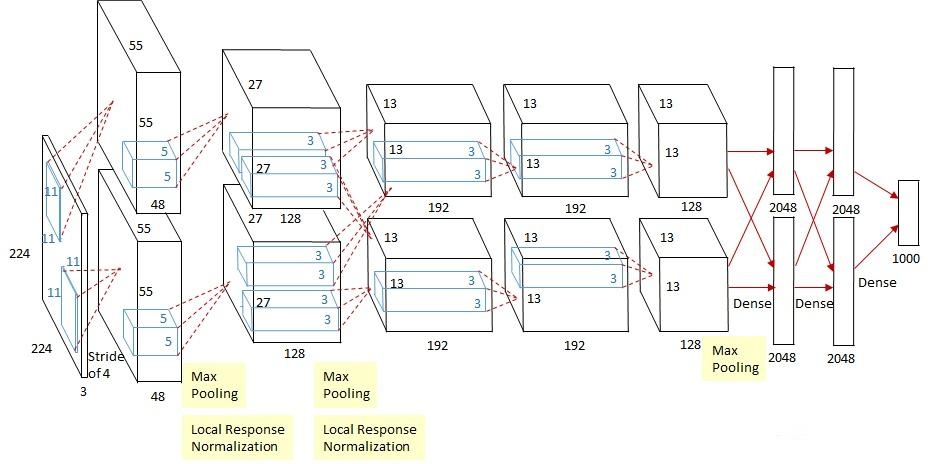
*卷积层(Convolutional Layer)*
卷基层用来实现特征提取,将2个函数进行叠加,应用在图像上,找出图像中的某些特征,由于需要找到很多特征才能区分某一物体,所以会有多个滤镜,通过这些滤镜的组合,我们可以得出很多的特征。
卷积层中有三个重要参数
深度/depth(解释见下图)
步幅/stride (窗口一次滑动的长度)
填充值/zero-padding
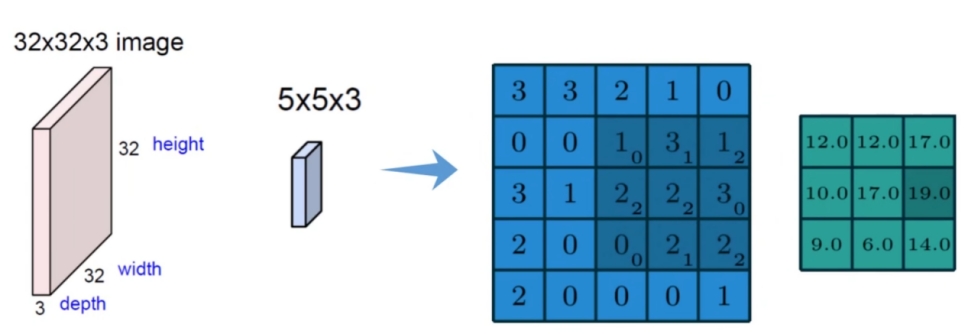
*步幅*
步幅控制着过滤器围绕输入内容进行卷积计算的方式。想象一个 7 x 7 的输入图像,一个 3 x 3 过滤器(简单起见不考虑第三个维度),步幅为 1。这是一种惯常的情况。
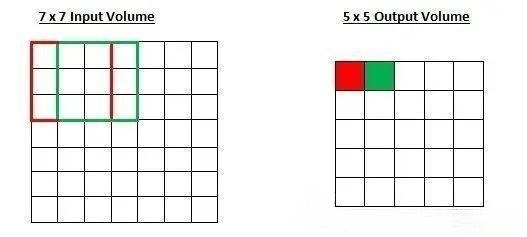
如果步幅增加到 2
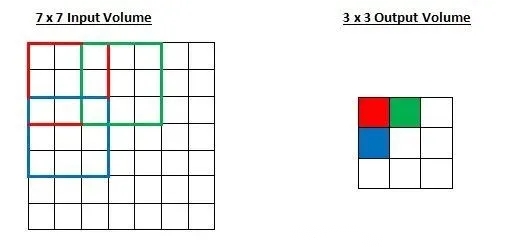
*填充值*
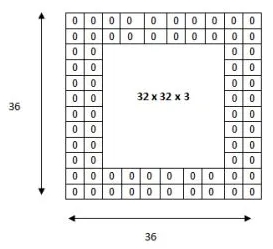
把 5 x 5 x 3 的过滤器用在 32 x 32 x 3 的输入上时,输出的大小会是 28 x 28 x 3。注意,这里空间维度减小了。如果继续用卷积层,尺寸减小的速度就会超过期望。在网络的早期层中,想要尽可能多地保留原始输入内容的信息,这样我们就能提取出那些低层的特征。比如说我们想要应用同样的卷积层,但又想让输出量维持为 32 x 32 x 3 。为做到这点,我们可以对这个层应用大小为 2 的零填充(zero padding)。零填充在输入内容的边界周围补充零。如果我们用两个零填充,就会得到一个 36 x 36 x 3 的输入卷。
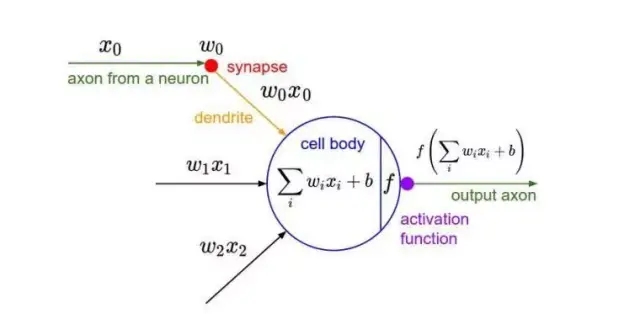
*非线性层(或激活层)*
激活层用于把卷积层输出结果做非线性映射。激活函数是激活层中用加入的非线性因素,能够提高网络表达能力,卷积神经网络中最常用的是ReLU,Sigmoid使用较少。
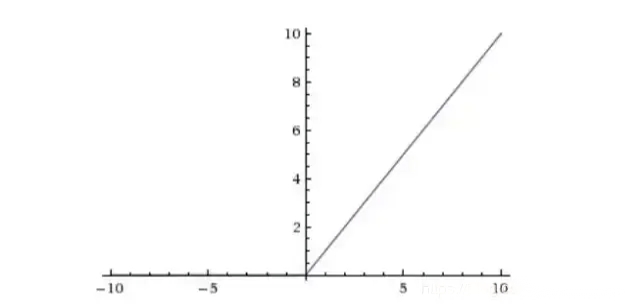
CNN采用的激活函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱,图像如下。
*池化层*
池化层夹在连续的卷积层中间,用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
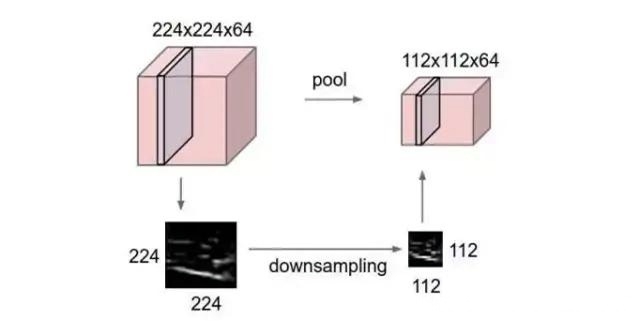
池化层的作用主要有三点:
特征不变性,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
特征降维,一幅图像含有的信息数量大,特征多,但是有些信息对于做图像任务没有太多用途,可以把这类冗余信息去除,把最重要的特征抽取出来。
在一定程度上防止过拟合,更方便优化。
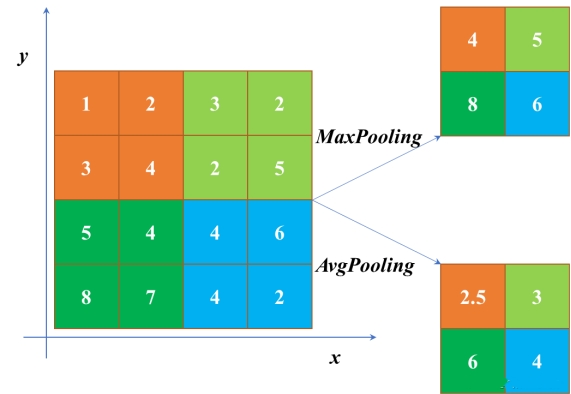
池化的具体方法主要分为以下两种,最大池化和平均池化,具体池化方法如图所示。
*改进与提升*
由于AlexNet模型所使用7*7的卷积核,较大的卷积核使其对于较深的网络结构需要更多的计算资源。因此从缩小卷积核的角度着手,产生了VGG网络模型结构。
3. *VGG*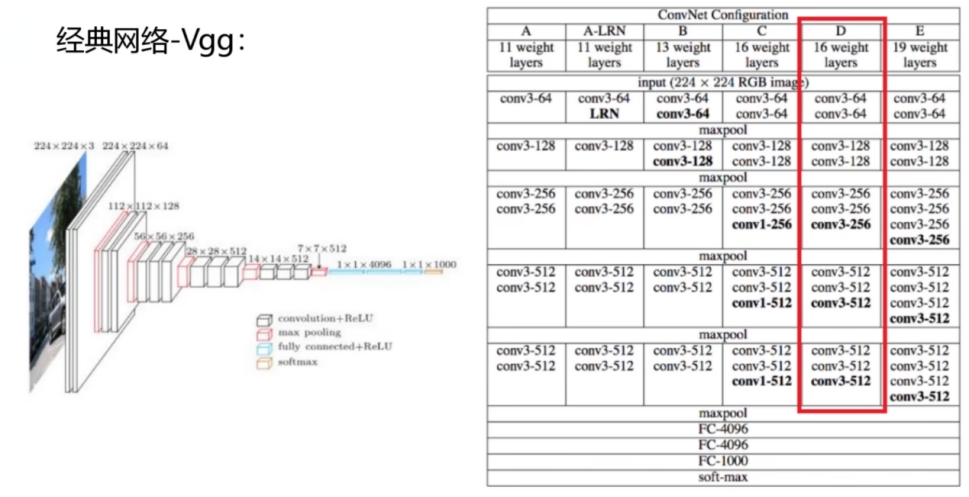
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
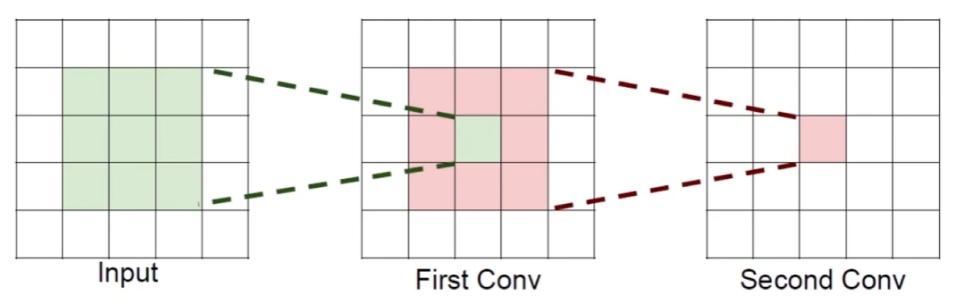
*感受野*
在卷积神经网络中,感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的神经元。感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次。
在刚才提到的VGG网络当中,假设输出大小都是hwc,并且使用c个卷积核,可以计算一下其格子所需参数:
7*7卷积核所需参数:
3个3*3卷积核所需参数:
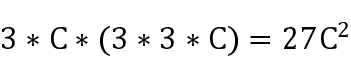
很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取也会越细致,加入的非线性变换也随着增多,还不会增大权重参数个数,这就是VGG网络的基本出发点,用小的卷积核来完成体特征提取操作。
在VGG的基础上进行进一步改进和优化,产生了残差网络Resnet。
4. *Resnet*
ResNet的主要创新是引入了残差结构,允许网络学习残差映射,而不是直接学习完整的特征映射。这有助于解决梯度消失问题,允许训练非常深的网络。
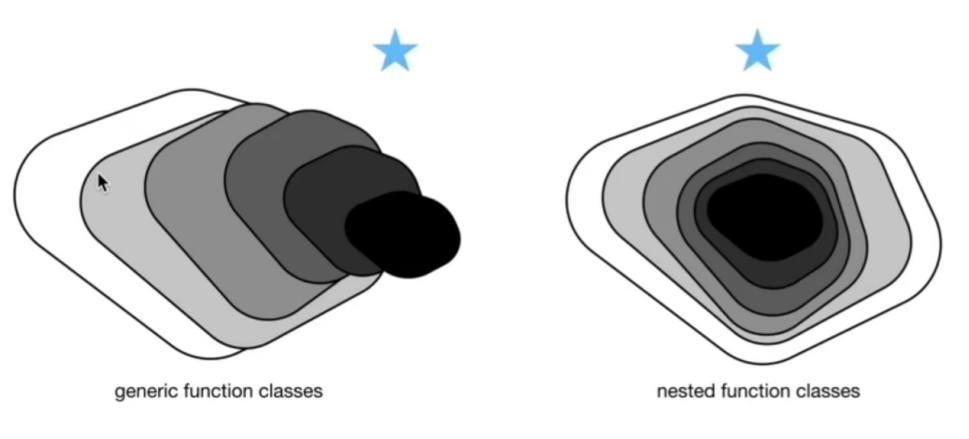
在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题。
l 梯度消失或梯度爆炸。
l 退化问题(degradation problem)。
ResNet论文提出了residual结构(残差结构)来减轻退化问题。使用residual结构的卷积网络,随着网络的不断加深,效果并没有变差,反而变的更好了。
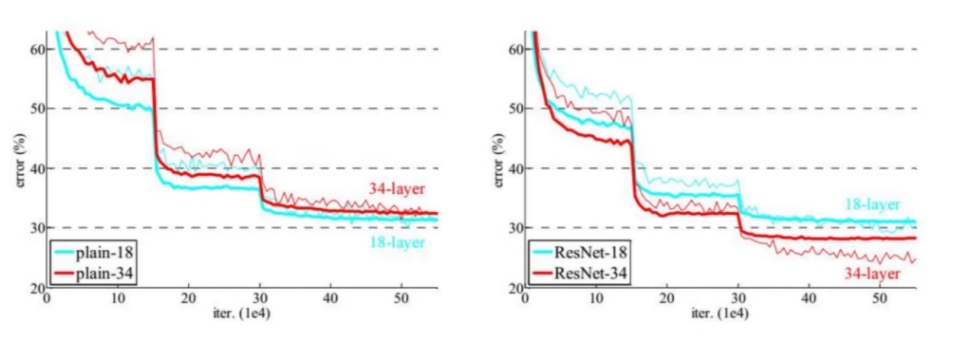
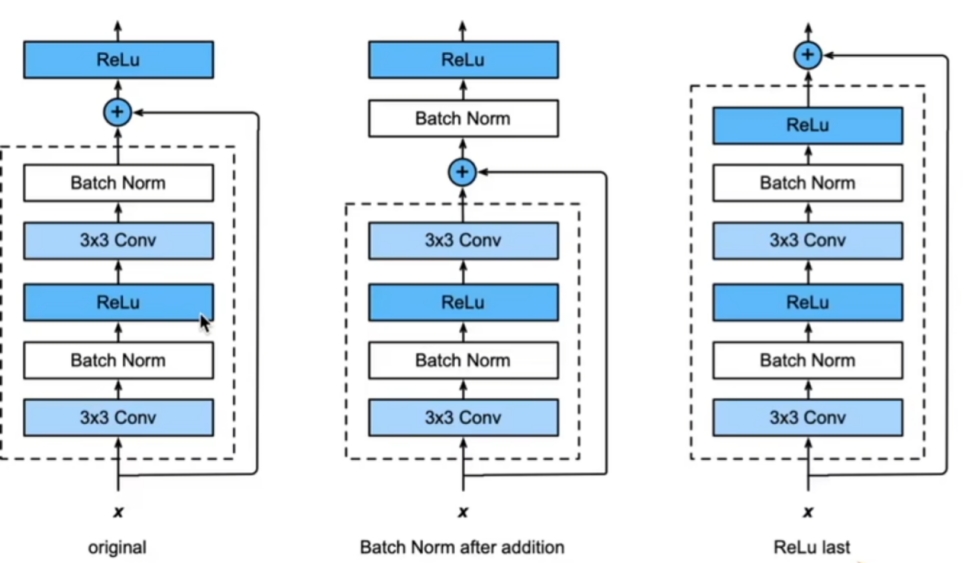
ResNet团队分别构建了带有“直连边(Shortcut Connection)”的ResNet残差块、以及降采样的ResNet残差块,区别是降采样残差块的直连边增加了一个1×1的卷积操作。对于直连边,当输入和输出维度一致时,可以直接将输入加到输出上,这相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。但是当维度不一致时,这就不能直接相加,通过添加1×1卷积调整通道数。这种残差学习结构可以通过前向神经网络+直连边实现, 而且整个网络依旧可以通过端到端的反向传播训练。结构如下图所示:
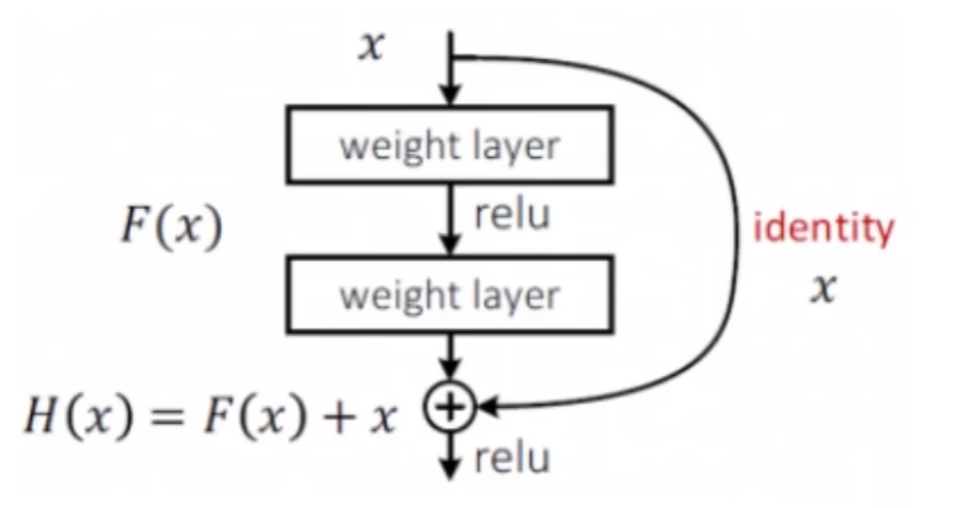
同时残差块也可以存在不同的格式,不同的残差块示例如下:
 *三、CNN网络实验*
*三、CNN网络实验*
*1. 背景介绍*
隐写分析是为了检测表面上无害的载体中是否存在机密消息(或秘密信息)。它是针对隐写术的对策技术,而隐写术则是将秘密信息嵌入数字载体的技术。
在本实验中,我们将检测一种新型的隐写术,它将多种正交隐写术方法应用于单个载体。所谓正交,即隐写方法的信息隐藏和提取过程独立运行。这种新型的隐写术有两个特点。首先,它是异构的,因为它使用两种或多种不同的隐写方法来隐藏信息。其次,它是并行的,因为每种隐写方法隐藏的机密消息都是单独嵌入的。因此,这种隐写术称为异构并行隐写术(HPS)。因此,使用一种隐写方法的传统隐写术称为单一隐写术。
流媒体,例如VoIP,是HPS的合适载体。流媒体是通过互联网以压缩形式发送的音频或视频内容。它由一系列包含协议标头和有效负载(例如音频和/或视频帧)的数据包组成。HPS可以应用于流媒体。以VoIP为例,在线性预测编码(LPC)过程中嵌入消息的隐写方法与将信息隐藏与基音周期预测相结合的隐写方法是正交的。因此,这两种隐写方法都可以为VoIP构建HPS。
本实验的目标是检测低比特率 VoIP 语音流(即一种广泛使用的流媒体)的 HPS。两种正交隐写方法,即量化索引调制(QIM)和音高调制隐写术(PMS),用于形成HPS。我们调研并使用了一种十分有效的深度模型,叫做隐写分析特征融合网络(SFFN)。SFFN结合了三种神经网络结构,即卷积神经网络(CNN)、循环神经网络(RNN)和全连接网络(FCN)。这种方法能够有效地融合HPS中使用的不同隐写方法提取的隐写分析特征,因此,我们的方法能够在检测低比特率VoIP语音流的HPS任务中实现高精度。
*2. 实验数据载体简介*
VoIP 是一种广泛使用的流媒体,由于其易于数据网络访问,为电话通信提供了一种经济的协议。由于综合分析LPC可以实现高压缩比和令人满意的语音质量,因此基于LPC的低比特率语音编解码器,例如G.723.1和G.729,被广泛应用于VoIP。对于这些编解码器,在对语音进行编码的过程中,信息可以隐藏在有效负载(即语音帧)上。
基于低比特率VoIP语音流有效负载的隐写方法可以大致分为两类。第一类是在LPC编码过程中隐藏秘密消息,例如互补邻居顶点(CNV)来改进QIM的码本划分。在CNV-QIM中,秘密信息嵌入到语音的线谱对(LSP) 参数中。第二类将信息隐藏集成到基音周期预测中,这些方法也称为音调调制隐写术(PMS)。在PMS中,通过修改自适应码topic延迟(ACD)参数,将机密消息隐藏在语音中。
由于QIM和PMS涉及独立的语音编码过程,因此这两种隐写方法是正交的,并且可以用于形成低比特率VoIP语音流的HPS。
*3. 具体的方法(SFFN)*
*3.1. 数据处理*
首先,我们需要分析 VoIP 的哪些框架部分被 QIM 和 PMS 修改。对于QIM,它在矢量量化过程中嵌入隐藏消息以计算LSP系数。因此,使用从编码语音中提取的 LSP 码字作为 QIM 的隐写分析描述符。与 QIM 不同,PMS 在音调分析过程中隐藏秘密信息,并根据隐藏信息修改音调延迟。由于音调延迟被编码为 ACD 码字,因此需要将 ACD 码字解码为音调延迟并将其用作 PMS 隐写分析描述符,以避免编码的不良影响。 QIM 和 PMS 隐写分析描述符都用作SFFN方法的输入数据。
通过对G.729a语音流处理后,我们得到了针对QIM和PMS两种隐写方法分析的描述符,其形状分别为(3,T)和(4,T),其中T为语音帧个数,在 G.729 编解码器中,我们选取帧长度为10ms,因此对于1s的语音流而言,我们能够从中提取出100个语音帧,因此T为100。即我们从每个1s的语音流样本中提取出了(3,100)和(4,100)两部分隐写分析描述符,以作模型输入。
*3.2. 网络架构*
SFFN方法的整体网络结构如下图所示,其中包含三个子网络:特征学习网络、特征融合网络和分类网络。特征学习网络用于从输入数据中学习每个隐写术的隐写分析特征。特征融合网络用于融合特征以生成联合特征以进行最终预测。分类网络利用联合特征来预测隐藏消息存在的概率。在本实验中,我们采用交叉熵损失函数。
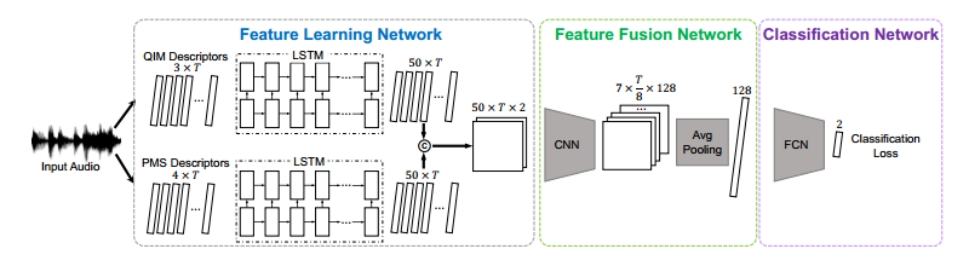
3.2.1. 特征学习网络
特征学习网络由两个堆叠的长短期记忆(LSTM)网络组成。LSTM是RNN的一种变体,它可以有效地处理语音和文本等序列数据。在特征学习网络中,第一个 LSTM 来学习 QIM 的隐写分析特征。第二个LSTM来学习PMS的特征。两个 LSTM 都有两个堆叠层,每层隐藏状态的维度都设置为50。最终,两个LSTM网络的输出形状均为(50,T)。最后,两个形状均为(50,T)的输出数组被连接并重塑为3D联合数组,记为M,其形状为(50,T,2)。
3.2.2. 特征融合网络
SFFN利用CNN将两种隐写方法的隐写分析特征融合到一个联合特征向量中。在本实验中,采用精心设计的CNN来提取HPS检测的高级特征,下图3展示了 CNN 的详细结构。
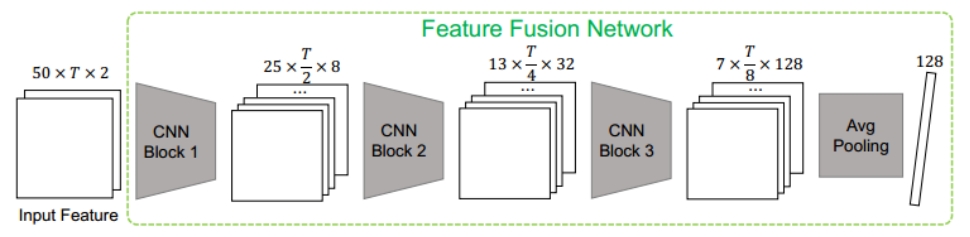
特征融合网络由三个CNN块组成。前两个块分别由两个3×3卷积层、一个步长为2的最大池化层和一个ReLU激活层组成。最后一个块包含两个3×3卷积层、一个ReLU激活层和一个全局平均池化层。在这些块中,每个卷积层将通道数加倍,以便最终卷积层的输出具有128个通道。前两个块中的最大池化层将特征图的宽度和高度减少一半。同时,最后一个块中的全局平均池化层计算每个通道的平均值,从而输出1×1×128的数组。最后,全局平均池化层的输出被重塑为128维的向量。
3.2.3. 分类网络
这一网络模块是一个FCN,用于根据特征融合网络计算的联合特征来预测隐藏消息存在的概率。FCN由全连接 (FC)层和softmax激活层组成。FC层的输出大小为2。
*3.3. 训练过程*
整体训练过程分为三个阶段。在第一阶段,使用两个辅助FCN(即两个额外的分类器网络)预训练特征学习网络。在第二阶段,通过最小化分类损失仅更新特征融合网络(CNN)和分类网络的参数。在第三阶段,对三个子网络的所有参数进行微调。
对于此方法而言,从头开始训练整个子网络很难实现,特别是当语音中秘密信息的嵌入率较低时。因此为了解决这个问题,我们需要对特征学习网络进行预训练。具体来说,即利用交叉熵损失来预训练两个LSTM。对于特征学习网络的每个LSTM,我们将LSTM的最终隐藏状态馈送到FCN以生成2维向量。2维向量中的元素表示语音中存在和不存在隐藏消息的概率。接下来,我们对三个阶段分别进行概括。
第一阶段:在此阶段,首先随机初始化特征学习网络中两个 LSTM 的参数。然后,通过使用辅助FCN最小化交叉熵损失来单独训练每个LSTM。这个预训练阶段可以促进后期分类损失的收敛。
第二阶段:在此阶段,首先用随机值初始化特征融合网络和分类网络的参数。然后,通过最小化分类损失来更新它们。由于特征学习网络已在第一阶段进行了优化,因此我们在此阶段进一步训练其参数。
第三阶段:在这个阶段,对三个子网络的所有参数进行微调。优化目标与第二阶段相同。从实验结果来看,与第二阶段相比,对三个子网络的整体参数进行微调可以实现分类精度的稳定提高。
经过上述三个阶段训练后,SFFN方法能够实现HPS的高精度检测。
*4. 实验设计及实验结果*
*4.1. 数据集构建*
我们使用814,592条G.729a语音构成数据集进行实验。其中,764,592个样本(382,296个Stego-Cover对,即正负样本对)被划分为训练集,其余50,000个作为测试集。数据集中所有样本的持续时间均为1秒。
在训练集的正样本中,QIM隐写样本数与PMS隐写样本数之比为1:1。如上所述,正负样本比也为1:1,因此训练集的样本是平衡的,这样更加有利于模型的训练,增强测试效果。
*4.2. 模型效果*
如下表所示,在检测HPS时, SFFN方法在所有嵌入率下均取得了最佳性能。在嵌入率为100%的情况下进行HPS分类的准确率高达 91.65%,当以大于60%的嵌入率检测CNV-QIM时,SFFN方法可以达到高于84.90%的分类精度。实验结果表明,该方法在CNV-QIM、PMS以及HPS检测上均取得了令人满意的精度。
| Steganalysis method | Steganography Method | Embedding Rate (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 | ||
| SFFN | CNV-QIM | 54.28 | 54.62 | 71.23 | 65.08 | 82.19 | 84.90 | 87.43 | 89.66 | 91.86 | 93.50 |
| PMS | 51.17 | 53.76 | 61.52 | 63.94 | 69.74 | 72.80 | 76.11 | 79.07 | 82.04 | 83.93 | |
| CNV-QIM + PMS | 66.67 | 70.44 | 77.81 | 75.01 | 84.37 | 87.66 | 88.44 | 89.66 | 91.08 | 91.65 |
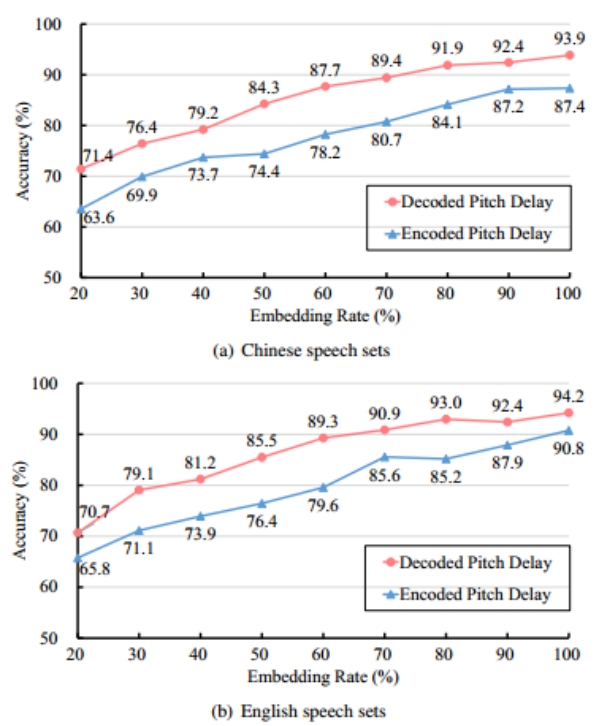
在本实验中,对于PMS隐写检测而言,我们比较了采用基音延迟或ACD码字作为PMS描述符时的平均准确度。结果如下所示。通过查阅资料可知,尽管有许多学者建议使用ACD码字,但在与SFFN方法中使用ACD码字相比,使用音调延迟可带来大约5%到10%的分类精度提高。结果表明,基音延迟比 ACD 码字更适合SFFN网络提取隐写分析特征。
*4.3. 消融实验*
为了探索微调的好处,我们比较了第三阶段网络所有参数微调之前和之后在不同隐写嵌入率下的平均检测精度。
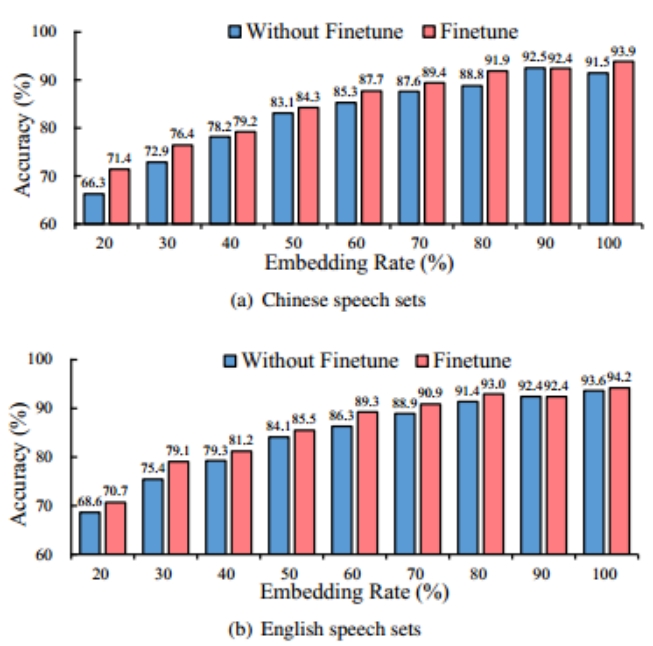
下图显示了SFFN方法在有和没有微调阶段的结果,可以观察到微调可以带来精度的提高,特别是当嵌入率较低时。例如,当中文语音和英语语音的嵌入率为 30% 时,SFFN方法在微调后的准确率分别比微调前高出3.5%和3.7%。在其他设置下也可以观察到类似的准确性提高。结果表明,在第三阶段对整个子网络进行微调有利于SFFN方法提高分类精度。
*4.4. 实时性测试*
为了进行在线隐写分析,需要实时进行检测。因此评估了SFFN方法对不同长度的语音(即0.1s、0.2s、…、1s和2s)的检测时间。实验在配备AMD Ryzen 7 5700X 8-Core CPU的平台上进行。此外,GPU不用于加速测试。经过实验,我们测得SFFN方法需要0.34毫秒来检查10毫秒的单个语音帧。因此,本实验表明SFFn方法满足实时隐写分析的要求。
*5. 总结*
在本实验中,我们完成了检测流媒体上的异构并行隐写术(HPS)这一任务。具体来说,实验关注特定的介质,即低比特率 VoIP 语音流,HPS 由两种正交隐写方法(即QIM和PMS)形成。我们使用了一种名为隐写分析特征融合网络(SFFN)的深度模型来解决该任务。SFFN可以有效地提取HPS中使用的隐写方法的隐写分析特征,并融合这些特征以做出可信的预测。在实验中,SFFN在检测HPS时表现出了十分良好的性能。此外,SFFN方法可以满足实时检测的要求,例如检查10 ms的语音帧只需要0.34 ms。
 wechat
wechat- alipay





