
编译原理与技术课程笔记
编译原理与技术 郭燕慧
引论
编译器的结构
| Lexical Analyzer | 词法分析 |
|---|---|
| Syntax Analyzer | 语法分析 |
| Semantic Analyzer | 语义分析 |
| Intermediate Code Generator | 中间代码生成 |
| Machine-Independent Code Optimizer | 机器无关的代码优化 |
| Code Generator | 代码生成 |
| Machine-Dependent Code Optimizer |
前端
- 将源程序分解为多个组成部分,并对其施加语法结构
- 使用语法结构创建一个中间表示intermediate representation(IR)的源程序
- 收集有关源程序的信息,并将其存储在称为符号表的数据结构中(将通过IR传递给后端)
后端
- 根据IR和符号表中的信息构造目标程序(通常用机器语言)
- 在此过程中执行代码优化
词法分析 Lexical Analyzer
<token-name, attribute-value>
position = initial + rate * 60
Lexical Analyzer
<id, 1>
<=>
<id, 2>
<+>
<id, 3>
<*>
<60>
语法分析 Syntax Analyzer
语法分析器(解析器)使用词法分析器生成的令牌名称来创建描述令牌流语法结构的中间表示,通常是语法树
每个内部节点表示一个操作,该节点的子节点表示该操作的参数
语义分析 Semantic Analysis
语义分析器使用语法树和符号表中的信息来检查源程序与语言定义的语义一致性
还收集用于类型检查、类型转换和中间代码生成的类型信息
编程语言的语法描述了其程序的适当形式
编程语言的语义描述了其程序的含义,即每个程序在执行时所做的事情
类型检查 Type Checking
语义分析的一个重要部分是类型检查编译器检查每个操作符是否有匹配的操作数(类型正确)
中间代码生成 Machine-Independent Code Optimizer
- 经过语义分析后,编译器生成一个中间值representation, typically three-address code (Three-address code)
- 类汇编指令,每条指令有三个操作数,每个操作数就像一个寄存器
- 每个赋值指令在RHS上最多有一个操作符
- 易于翻译成目标机器的机器指令
机器无关的代码优化 Machine-Independent Code Optimization
类似于英文的文章编辑/修改,改进中间代码以获得更好的目标代码
t1 = inttofloat(60)
t2 = id3 * t1
t3 = id2 + t2
id1 = t3
—>
t1 = id3 * 60.0
id1 = id2 + t1
代码生成 Code Generator
t1 = id3 * 60.0
id1 = id2 + t1
Code
Generation
LDF R2, id3
MULF R2, R2, #60.0
LDF R1, id2
ADDF R1, R1, R2
STF id1, R1
符号表管理
- 由前端执行,符号表与中间代码一起传递到后端
- 记录变量名称和存储分配的各种属性、类型、作用域
- 记录过程名称和各种属性
- 参数的数量和类型
- 传递参数的方式(通过值或引用)
- 返回类型
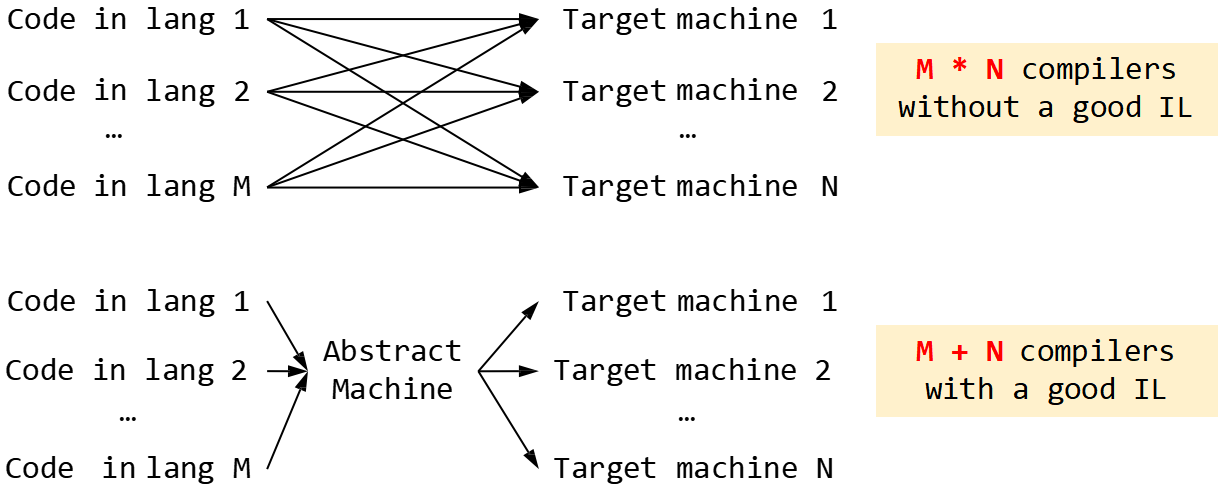
中间语言(Intermediate Language)IL
编译器与解释器的区别
1
编译器将用高级语言编写的源程序翻译成可以直接在目标计算机上运行的机器码。
解释器直接执行源代码中的每条语句,而不需要将程序编译成机器码。
2
解释器通常花费较少的时间来分析源代码:他们只是解析每个语句并执行它(例如,Python代码)。
相比之下,编译器通常会分析语句之间的关系(例如,控制流和数据流)以实现优化。
3
解释器继续执行程序,直到遇到第一个错误,在这种情况下它们停止。
对于编译语言,程序只有在编译成功后才可执行。
编译器的结构
| Lexical Analyzer | 词法分析 |
|---|---|
| Syntax Analyzer | 语法分析 |
| Semantic Analyzer | 语义分析 |
| Intermediate Code Generator | 中间代码生成 |
| Machine-Independent Code Optimizer | 机器无关的代码优化 |
| Code Generator | 代码生成 |
| Machine-Dependent Code Optimizer |
前端
- 将源程序分解为多个组成部分,并对其施加语法结构
- 使用语法结构创建一个中间表示intermediate representation(IR)的源程序
- 收集有关源程序的信息,并将其存储在称为符号表的数据结构中(将通过IR传递给后端)
后端
- 根据IR和符号表中的信息构造目标程序(通常用机器语言)
- 在此过程中执行代码优化
词法分析 Lexical Analyzer
<token-name, attribute-value>
position = initial + rate * 60
Lexical Analyzer
<id, 1>
<=>
<id, 2>
<+>
<id, 3>
<*>
<60>
语法分析 Syntax Analyzer
语法分析器(解析器)使用词法分析器生成的令牌名称来创建描述令牌流语法结构的中间表示,通常是语法树
每个内部节点表示一个操作,该节点的子节点表示该操作的参数
语义分析 Semantic Analysis
语义分析器使用语法树和符号表中的信息来检查源程序与语言定义的语义一致性
还收集用于类型检查、类型转换和中间代码生成的类型信息
编程语言的语法描述了其程序的适当形式
编程语言的语义描述了其程序的含义,即每个程序在执行时所做的事情
类型检查 Type Checking
语义分析的一个重要部分是类型检查编译器检查每个操作符是否有匹配的操作数(类型正确)
中间代码生成 Machine-Independent Code Optimizer
- 经过语义分析后,编译器生成一个中间值representation, typically three-address code (Three-address code)
- 类汇编指令,每条指令有三个操作数,每个操作数就像一个寄存器
- 每个赋值指令在RHS上最多有一个操作符
- 易于翻译成目标机器的机器指令
机器无关的代码优化 Machine-Independent Code Optimization
类似于英文的文章编辑/修改,改进中间代码以获得更好的目标代码
t1 = inttofloat(60)
t2 = id3 * t1
t3 = id2 + t2
id1 = t3
—>
t1 = id3 * 60.0
id1 = id2 + t1
代码生成 Code Generator
t1 = id3 * 60.0
id1 = id2 + t1
Code
Generation
LDF R2, id3
MULF R2, R2, #60.0
LDF R1, id2
ADDF R1, R1, R2
STF id1, R1
符号表管理
- 由前端执行,符号表与中间代码一起传递到后端
- 记录变量名称和存储分配的各种属性、类型、作用域
- 记录过程名称和各种属性
- 参数的数量和类型
- 传递参数的方式(通过值或引用)
- 返回类型
中间语言(Intermediate Language)IL
编译器与解释器的区别
1
编译器将用高级语言编写的源程序翻译成可以直接在目标计算机上运行的机器码。
解释器直接执行源代码中的每条语句,而不需要将程序编译成机器码。
2
解释器通常花费较少的时间来分析源代码:他们只是解析每个语句并执行它(例如,Python代码)。
相比之下,编译器通常会分析语句之间的关系(例如,控制流和数据流)以实现优化。
3
解释器继续执行程序,直到遇到第一个错误,在这种情况下它们停止。
对于编译语言,程序只有在编译成功后才可执行。
第二章词法分析器
词法分析器的作用
- 读取输入字符的源程序,将它们转换为词素,并生成一个标记序列
- 必要时向符号表中添加词素去掉注释和空白(空白、换行、制表符等)。
- 将错误消息与行号关联(跟踪换行)
有效执行简单任务、提高编译器效率(比语法分析简单的多)、提高编译器可移植性
Tokens, Patterns, and Lexemes
token由一对<token name, attribute value>组成,<抽象符号,字符表内容>
patterns是对tokens的词素可能采取的形式的描述。
lexeme就是所表示的实例
例子:printf(“Total =%d\n”, score)
| Lexeme | printf | scorce | “Total =%d\n” | ( | … |
|---|---|---|---|---|---|
| Token | id | id | literal | left_parenthesis | … |
token属性
token name:影响属性决策
attribute value:影响代码分析生成
令牌规范(正则表达式)
Regular expression (正则表达式,regexp)指词素模式的重要符号
- Strings and Languages (串和语言)
- Operations on Languages (语言上的运算)
- Regular Expressions
- Regular Definitions (正则定义)
- Extensions of Regular Expressions
字符串和语言
Alphabet(字母表):任何有限的符号集合
符号的例子:字母、数字和标点符号
字母的例子:(1,0),ASCII, Unicode
string(串)是从字母表中抽取的符号的有限序列
字符串s的长度,记为Isl,是数符号在s中的出现次数(即基数)
Empty string(空字符串):长度为0,ε
与字符串相关的术语
Prefix 前缀:从的末尾删除0个或多个符号获得的任何字符串。
Proper prefix 真前缀:不是ε也不等于s本身的前缀。
Suffix 后缀:从s 的开头删除0个或多个符号后获得的任何字符串。
Proper suffix 真后缀:非ε且不等于s的后缀本身
Substring (子串):从s中删除任何前缀和后缀而得到的任何字符串。
Proper substring (真子串):不是ε且不等于s本身的子字符串。
Subsequence (子序列):从s中去掉0个或多个不一定连续的符号而形成的字符串
Concatenation (连接):x = dog, y = house, xy = doghouse
Exponentiation (幂/指数运算):
$$
x = dog, x^0 = ε,x^1 = dog,x^3 = dogdogdog
$$
language (语言):任何可数集合的一些固定字母
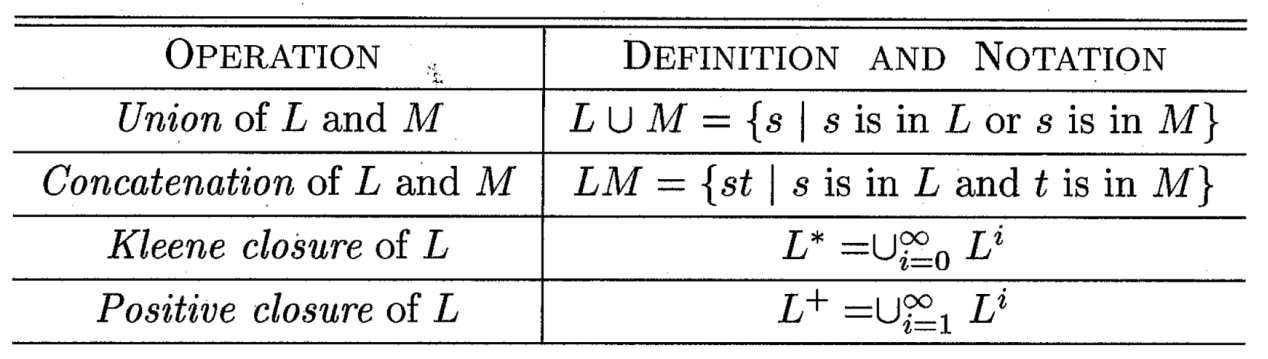
Operations on Languages (语言的运算)
优先级:closure*> concatenation > union
令牌识别(转换图)
词法分析器检查输入字符串并找到一个前缀匹配其中一个标记
构建词法分析器的第一件事是使用常规定义定义令牌的模式
一个特殊的token: ws→(blank I tab I newline)*
Transition Diagrams (状态转换图)
构造词法分析器的一个重要步骤是将模式转换为“转换图”。
转换图有一组节点,称为状态(state)和边缘(edge),从一个节点指向另一个节点
States
起始状态由标记为“start”的边表示,它从任何地方进入
接受状态,或者是最终的,表明已经找到了一个词素
States Cont
在某些接受状态下,找到的词素可能不包含我们从开始状态看到的所有字符
这样的状态用*来注释当进入状态时,需要收回指向输入字符串中下一个字符的前向指针。
Edges
边从一种状态指向另一种状态
每条边都用一个或一组符号来标记
Recognition of Reserved Words and Identifiers (保留字和标识符的识别)
在许多语言中,保留词或关键字(例如,then)还要匹配标识符的模式
构建整个词法分析器
策略1:依次尝试每个令牌的转换图
Fail()向前重置指针并开始下一个图表
策略2:并行运行转换图
需要解决一个图找到一个词素,而其他图仍然能够处理输入的情况。
解决方案:使用与任何模式匹配的最长的输入前缀
策略3:将所有转换图组合为一个(首选)
允许转换图读取输入,直到没有可能下一个状态取与任何模式匹配的最长词素
词法分析器生成器
Lex程序有三个部分,用%%分隔
- Declaration (声明)
- Translation rules (转换规则)
- Auxiliary functions section (辅助函数)
Finite Automata (有穷自动机)
Nondeterministic finite automata (NFA, 非确定有穷自动机)
当一个状态面对一个输入符号的时候,所转换到的是一个唯一确定的状态。
S = {0, 1, 2, 3}
Start state: 0
Accepting states: {3}
Transition function
▪ (0, a) → {0, 1} (0, b) → {0}
▪ (1, b) → {2} (2, b) → {3}
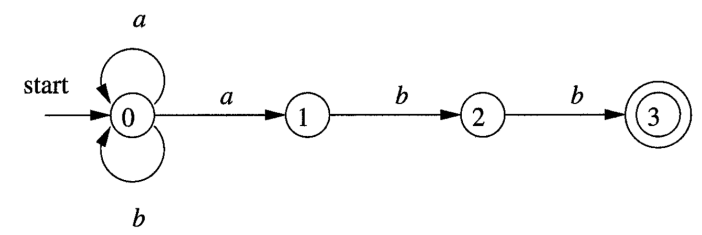
Transition Table 转换表

Deterministic finite automata (DFA, 确定有穷自动机)
当一个状态面对一个输入符号的时候,它所转换到的可能不只一个状态,可以是一个状态集合。
第三章:语法分析
描述语法
编程语言结构的语法可以通过上下文无关语法或BNF(Backus Naur Form)表示法指定
语法为编程语言提供了精确但易于理解的语法规范
对于某些语法,我们可以自动构建一个高效的解析器
设计得当的语法定义了一种语言的结构,有助于将源程序翻译成正确的目标代码并检测错误
语法允许通过添加新的结构来执行新的任务来迭代地进化或开发一种语言
语法分析器的角色
- 语法分析器从词法分析器获得token串,并验证token名称是否可以由源语言的语法生成
- 以智能的方式报告语法错误
- 对于格式良好的程序,语法分析器构建一个语法分析树
语法分析树无需显式构建
语法分析器的分类
· 通用语法分析器
· 一些方法(例如,Earley算法1)可以解析任何语法
· 然而,它们效率太低,无法在实践中使用
· 自顶向下语法分析器
· 构建从顶部(根)到底部(叶)的语法分析树
· 自底向上语法分析器
·从底部(叶子)到顶部(根)构建语法分析树
注意:自上而下和自下而上的解析都从左到右扫描输入,一次扫描一个符号。它们只适用于某些语法,这些语法具有足够的表达能力。
Context-Free Grammar (上下文无关文法)
上下文无关语法(CFG)由四个部分组成:
· Terminals终结符号: 形成字符串的基本符号(token名称)
· Nonterminals非终结符号: 表示字符串集的语法变量 通常对应于一个语言结构,如stmt(statements) 一个非终结符被区分为开始符号 由开始符号表示的字符串集是CFG生成的语言
·Productions 产生式: 指定终结符号和非终结符号组合形成字符串的方式
格式:head(左侧)-> body(右侧)
head是非终结符号;body由零个或多个终结符号或非终结符号组成
例如:expression -> expression + term
下面的语法定义了简单的算术表达式
Terminal symbols: id, +, -, *, /, (, )
Nonterminals: expression, term, factor
Start symbol: expression
Productions:
expression → expression + term
expression → expression – term
expression → term
term → term * factor
term → term / factor
term → factor
factor → ( expression )
factor → id
符号简化
E → E + T | E – T | T
T → T * F | T / F | F
F → ( E ) | id
“|”是指定备选方案的元符号
“(”和”)”不是元符号,而是终结符号
Derivation (推导)
推导: 从开始符号开始,使用产生式重写非终结符,直到只剩下终结符为止
符号
⇒ 意思是“一步到位”
⇒ ∗ 意思是“以零个或多个步骤推导” 𝛼 ⇒∗ 𝛼 适用于任何字符串𝛼
⇒ “ 意思是“以一个或多个步骤推导”
术语
• 如果S⇒ ∗ α, 其中S是语法G的开始符号,我们说α是G文法的句型
· 文法的句型可以同时包含终结符号和非终结符号,并且可以为空
· 示例𝐸 ⇒ −𝐸 ⇒ −(𝐸)⇒ −(𝐸+𝐸) ⇒ −(𝐢𝐝+𝐸) ⇒ −(𝐢𝐝 + 𝐢𝐝) 这里所有的语法符号串都是文法的句型
• 一个G的句子是一个没有非终结符的文法句型
· 在上面的例子中,只有最后一个字符串−(𝐢𝐝 + 𝐢𝐝)是一个句子
•语法产生的语言是它的一组句子
最左/最右推导
在推导的每一步,我们都需要选择要替换的非终结符
在最左推导中,总是选择每个句型中最左边的非终结符来替换
在最右推导中, 总是选择最右边的非终结符来替换
语法分析树
语法分析树是一种推导的图形表示,它过滤掉了产生式应用的顺序
· 根结点是文法的开始符号
· 每个叶子结点由终结符或𝜖标记
· 每个内部结点由非终结符标记
· 每个内部结点代表产生式的应用
· 内部节点用产生式的头部中的非终结符进行标记;
· 子节点由产生式主体中的符号从左到右进行标记
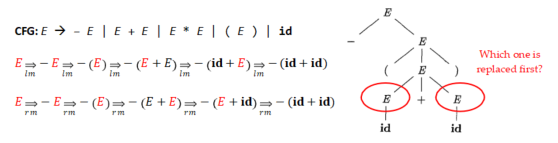
Ambiguity (二义性)
如果一个语法为某个句子生成了多个语法分析树,则它具有二义性
示例:该文法为id+id*id生成了两种语法分析树。
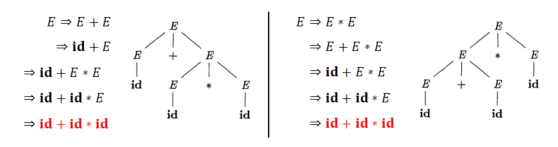
程序设计语言的语法通常需要明确
· 否则,将有多种方法来解释程序
· 问题:给定𝐸 → 𝐸 + 𝐸 | 𝐸 ∗ 𝐸 | (𝐸) | 𝐢𝐝, 如何解读 𝑎 + 𝑏 ∗ 𝑐?
· 答案:该文法是上一张PPT的示例,根据两种语法分析树,第一种解释:应先处理b*c,然后与a相加;第二种解释:应先处理a+b,然后与c相乘
在某些情况下,使用精心选择的歧义语法以及消歧规则来丢弃不需要的语法分析树是很方便的
CFG与正则表达式比较 CFG vs. Regular Expressions
CFG比正则表达式更具表达能力
· 可以用正则表达式描述的每个构造都可以用语法描述,但反之不成立
· 每个正则语言都是上下文无关的语言,但反之不成立
示例:$𝐿 ={𝑎^𝑛𝑏^𝑛 | 𝑛> 0}$
语言L可以用CFG:𝑆 → 𝑎𝑆𝑏 | 𝑎𝑏 来描述
L不能用正则表达式来描述。换句话说,我们不能构造一个DFA来接受L
任何正则语言都可以用CFG描述
(结构证明)NFA可以接受每种常规语言。我们可以构造一个CFG来描述语言:
· 对于每个在NFA中的状态 𝑖 ,创建一个非终结符𝐴𝑖
· 如果状态𝑖 在碰到输入a转为状态j 时, 添加产生式$𝐴_𝑖→ 𝐴_j$
· 如果状态𝑖 是一个接受状态,添加产生式𝐴𝑖→𝜖
· 如果状态𝑖 是开始状态,将𝐴𝑖作为文法的开始符号
语法设计
CFG能够描述编程语言的大部分(但不是全部)语法
· CFG不能描述“使用前应声明标识符”
· 后续阶段必须分析解析器的输出,以确保符合此类规则
在解析之前,我们通常对语法进行几种转换,使其更适合解析
· 消除二义性
· 消除左递归
· 提取左公因子
消除二义性
接近原则:用最接近的未匹配的then匹配else
· 重写的想法:出现在then和else之间的语句必须匹配(不能以不匹配的the结束)
重写语法以消除歧义是困难的。没有指导这一过程的一般规则。
消除左递归
如果语法中存在一个非终结符A,使得某个字符𝛼有相关的产生式𝐴 ⇒+ 𝐴𝛼 ,则该语法为左递归语法
立即左递归: 语法有产生式𝐴 -> 𝐴𝛼
自顶向下分析方法无法处理左递归语法(自底向上的分析方法可以处理…)
消除立即左递归
简单语法:𝐴 → 𝐴𝛼 | 𝛽 它生成以符号𝛽开头的句子,后面跟零个或更多的𝛼’s
将语法替换为:
𝐴 → 𝛽A’
A’ → 𝛼A’ | 𝜖
它现在是右递归了
𝐴 → 𝐴𝛼1|…|𝐴𝛼𝑚|𝛽1|… | 𝛽𝑛
将语法替换为:
𝐴 →𝛽1A’ | … |𝛽nA’
A’ → 𝛼1A’ | … | 𝛼mA’ |𝜖
例子:
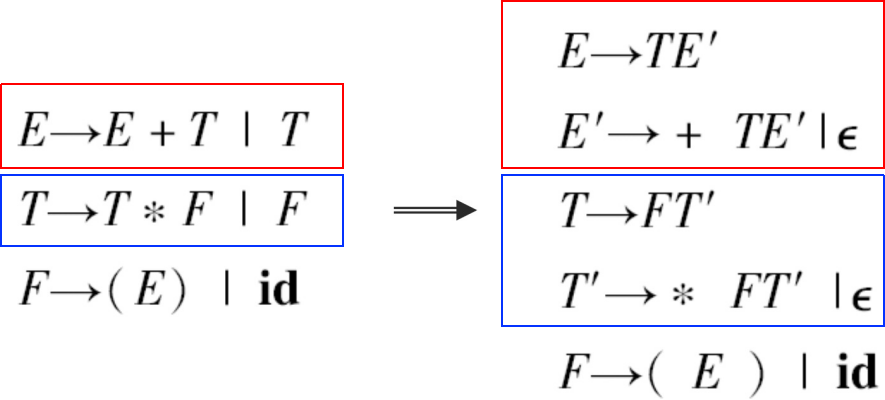
消除左递归
消除立即左递归的技术不适用于非立即左递归
通用左递归消除算法(迭代)
· 输入:没有循环或𝜖-产生式
· 输出:没有左递归的等价语法
Left Factoring (提取左公因子)
如果我们有以下两个产生式
𝑠𝑡𝑚𝑡 → 𝐢𝐟 𝑒𝑥𝑝𝑟 𝐭𝐡𝐞𝐧 𝑠𝑡𝑚𝑡 𝐞𝐥𝐬𝐞 𝑠𝑡𝑚𝑡 | 𝐢𝐟 𝑒𝑥𝑝𝑟 𝐭𝐡𝐞𝐧 𝑠𝑡𝑚𝑡
看到输入时𝐢𝐟, 我们无法立即决定选择哪个产生式
一般来说,如果𝐴 → 𝛼𝛽1 | 𝛼𝛽2是两个产生式,并且输入以从𝛼派生的非空字符串开始. 我们可以通过扩大𝐴 到𝛼𝐴‘来推迟选择产生式
自顶向下语法分析
问题定义:为输入字符串构建一个语法分析树,从根开始,按预序创建语法分析树的节点(深度优先)
· 相当于为输入字符串找到最左推导
基本思想(两个步骤):
· 预测:在解析的每一步,确定最左边非终结符所用的生产式
· 匹配:将所选产生式主体中的终结符与输入字符串相匹配
自底向上语法分析
问题定义:为输入字符串构建一个从叶子(终结符)开始并向上延伸到根(语法的开始符号)的语法分析树
· 相当于为输入字符串找到最右推导(相反)
移入-归约分析技术是自底向上语法分析的通用方式(使用栈来保存语法符号)
自底向上语法分析可以看作是一个将字符串𝜔“归约”到开始符号的过程
在每一个归约步骤中,与产生式主体匹配的特定子串(位于堆栈顶部)都会被产生式的头部替换(与推导步骤相反)
递归下降的语法分析
递归下降的语法分析程序对于每个非终结符都有一套程序
· 该程序会扫描与非终结符对应的结构(输入的子字符串)
从开始符号的程序开始执行
· 如果程序扫描整个输入字符串,则宣布成功
Backtracking (回溯)
一般的递归下降语法分析可能需要对输入进行重复扫描(回溯)
算法流程更改:
与考察A-产生式不同,我们必须按照一定的顺序尝试每一种可能的产生式。
当第7行出现故障时,返回第1行并尝试另一个A产生式
为了尝试另一个A-产生式时,我们必须重置指向下一个要扫描的符号的输入指针(失败尝试的消耗符号)
左递归带来的问题
如果CFG中有左递归,递归下降的语法分析器可能会进入无限循环,所以需要解析前修改CFG
𝐹𝐼𝑅𝑆𝑇()
假设输入字符串为𝒙𝒂
假设当前的句型是𝒙𝑨β
· 𝑨 是非终结符;β可以同时包含终结符和非终结符
如果我们知道产生式𝑨 → 𝑎 | 𝜸的以下事实:
·𝑎 ∈ 𝐹𝐼𝑅𝑆𝑇(𝛼) :𝛼 可以推导以a开头的字符串
·𝑎 ∉ 𝐹𝐼𝑅𝑆𝑇(𝛾):𝛾 不可以推导出以a开头的字符串
*𝐹𝐼𝑅𝑆𝑇(𝛼) 表示可从α推导得到的串的首符号的集合
计算FIRST(𝑿) 𝑋 是语法符号
· 如果𝑋 是一个终结符,那么FIRST(𝑋) = {𝑋}
· 如果X是一个非终结符,且𝑋 → 𝑌1𝑌2 … 𝑌𝑘 (𝑘 ≥ 1) 是一个产生式
· 如果对于某个𝑖,𝑎在FIRST(𝑌i)中且𝜖在所有的FIRST(𝑌1), …, FIRST(𝑌i-1)中,就把𝑎加入到FIRST(𝑋)中
· 如果对于所有的FIRST(𝑌1), …, FIRST(𝑌𝑘),𝜖在其中,那么将𝜖加入到FIRST(𝑋)中
· 如果X是一个非终结符,并且存在产生式𝑋 → 𝜖,那么将𝜖加入到FIRST(𝑋)中
计算FIRST(𝑿𝟏𝑿𝟐 … 𝑿𝒏) 𝑿𝟏𝑿𝟐 … 𝑿𝒏是语法符号的串
· 向FIRST(𝑋1𝑋2 … 𝑋𝑛)加入FIRST(𝑋1)中所有的非𝜖符号
· 如果𝜖在FIRST(𝑋1)中,再加入FIRST(𝑋2)中所有的非𝜖符号;如果𝜖在FIRST(𝑋1)和FIRST(𝑋2)中,加入FIRST(𝑋3)中的所有非𝜖符号,以此类推。
· 最后,如果对于所有的i,𝜖都在FIRST(𝑋i)中,那么将加入到FIRST(𝑋1𝑋2 … 𝑋𝑛)中。
假设输入字符串为𝒙𝒂
假设当前的句型是𝒙𝑨β
· 𝑨 是非终结符;β可以同时包含终结符和非终结符
如果我们知道生产𝑨 →𝛼, 𝜖 ∈ 𝐹𝐼𝑅𝑆𝑇(𝛼), 我们能选择重写A的产生式吗?
可以,只有在𝛽 可以推导以𝑎开头的字符串, 即,在一些句型中𝐴 后面可以跟着𝑎 (即,𝒂 ∈ 𝑭𝑶𝑳𝑳𝑶𝑾(𝑨))
计算FOLLOW集
计算所有非终结符A的FOLLOW(A)集合
· 将$反复到中,其中S是开始符号,二是输入右端的结束标记
· 不断应用下面的规则,直到所有FOLLOW集不再改变
· 如果存在一个产生式𝐴 → 𝛼𝐵𝛽,那么FIRST(𝛽)中除𝜖之外的所有符号都在FOLLOW(𝐵)
中
· 如果存在一个产生式𝐴 → 𝛼𝐵 ,或存在产生式𝐴 → 𝛼𝐵𝛽且FIRST(𝛽)包含𝜖,那么FOLLOW(𝐴)中的所有符号都在FOLLOW(𝐵)
中
𝜖不会在任何FOLLOW集中
LL(1) Grammars
我们可以为一类称为LL(1)的语法构造不需要回溯的递归下降语法分析器
从左到右扫描输入
产生最左推导
在每一步使用一个前瞻输入符号来作出分析决策
语法𝑮 是LL(1)当且仅当对于任意两个不同的产生式𝐴 → 𝛼 | 𝛽, 以下条件成立:
1.不存在终结符𝑎 使得𝛼 和𝛽 都可以推导以𝑎开头的字符串
2.𝛼 和𝛽 中最多只有一个可以推导空字符串
3.如果𝛽 ⇒* 𝜖, 那么𝛼 不能推导出任何以FOLLOW(𝐴)中某个终结符开头的字符串,反之亦然
*这三个条件基本上排除了应用两个产生式的可能性
更正式地说:
- FIRST(𝛼)∩ FIRST(𝛽)= ∅ (上述条件1-2)
如果𝜖 ∈ FIRST(𝛽),那么 FIRST(𝛼)∩ FOLLOW(𝐴)= ∅ ,反之亦然
对于LL(1)语法,在递归下降语法分析过程中,只需查看当前输入符号,就可以选择应用于非终结符的正确产生式:
给定文法
给出输入的分析步骤:
1.用产生式①重写开始符号stmt: 𝐢𝐟(𝐞𝐱𝐩𝐫)𝑠𝑡𝑚𝑡 𝐞𝐥𝐬𝐞 𝑠𝑡𝑚𝑡
2.用产生式②重写最左边的stmt:𝐢𝐟(𝐞𝐱𝐩𝐫)𝐰𝐡𝐢𝐥𝐞(𝐞𝐱𝐩𝐫) 𝑠𝑡𝑚𝑡 𝐞𝐥𝐬𝐞 𝑠𝑡𝑚𝑡
3.用产生式③重写最左边的stmt:𝐢𝐟(𝐞𝐱𝐩𝐫)𝐰𝐡𝐢𝐥𝐞(𝐞𝐱𝐩𝐫) 𝐚 𝐞𝐥𝐬𝐞 𝑠𝑡𝑚𝑡
4.用产生式③重写最左边的stmt:𝐢𝐟(𝐞𝐱𝐩𝐫)𝐰𝐡𝐢𝐥𝐞(𝐞𝐱𝐩𝐫) 𝐚 𝐞𝐥𝐬𝐞 a
Parsing Table (预测分析表)
递归下降语法分析器(或LL分析器)是基于表的解析器
预测分析表是一个二维数组,用于确定解析器在看到非终结符A和符号a时应该选择哪个产生式
LL(1)解析器的预测分析表没有包含多个产生式的条目
构造预测分析表
以下算法可以应用于任何CFG
输入:文法G
输出:预测分析表M
方法:对于每个产生式𝐴 → 𝛼 ,进行以下处理:
执行以下操作:
·对于FIRST(𝛼)中每个终结符𝑎,将𝐴 → 𝛼加入到𝑀[𝐴, 𝑎]
· 如果𝜖在FIRST(𝛼)中,对于FOLLOW(𝐴)中每个终结符b,包括$,将𝐴 → 𝛼加入到𝑀[𝐴, b]
将表中的所有空条目设置为错误
非递归的预测分析
非递归的预测分析器可以通过显式维护堆栈(而不是通过递归调用隐式维护)来构建
· 输入缓冲区包含要解析的字符串,以$结尾
· 堆栈包含底部为$的语法符号序列。
最初,堆栈只包含$和在$顶部的开始符号𝑆
表驱动的预测语法分析
输入:字符串𝜔 和文法G的预测分析表M
输出:如果𝜔 在𝐿(𝐺)中, 输出𝜔的一个最左边推导; 否则,给出一个错误指示
最初,输入缓冲区包含𝜔$
开始符号𝑆 位于堆栈顶部,在$上方。

自底向上分析
自底向上的语法分析
问题定义:为输入字符串构建一个从叶子(终结符)开始并向上延伸到根(语法的开始符号)的语法分析树
· 相当于为输入字符串找到最右边的推导(相反)
移入-归约分析技术是一种自底向上语法分析的通用方式(使用栈来保存语法符号)
Reductions (归约)
自底向上语法分析可以看作是一个将字符串𝜔“归约”到开始符号的过程
在每一个归约步骤中,与产生式体匹配的特定子串(位于栈顶部)会被产生式的头部替换(与推导步骤相反)
Handles (句柄)
非正式地讲,句柄是和某个产生式体匹配的子串,对它的归约代表了相应的最右推导中的一个反向步骤
正式地讲,如果$S \Rightarrow^*_{rm} \alpha A
\omega\Rightarrow^*_{rm} \alpha \beta
\omega$,那么紧跟𝛼的产生式𝐴 → 𝛽 (或者简单地𝛽) 是句型𝛼𝛽𝜔的一个句柄
Handle Pruning (句柄剪枝)
在最右句型中, 句柄右侧的字符串必须仅包含终结符号
如果一个文法是无二义性的,那么该文法的每个右句型都有且只有一个句柄
通过句柄剪枝可以得到一个反向的最右推导
移入-归约语法分析技术是自底向上语法分析的一种通用方式,其中:
· 使用栈保存文法符号
· 使用输入缓冲区保存要进行语法分析的字符串的其余部分
· 栈内容(从底部到顶部)和输入缓冲区内容形成最右句型(假设没有错误)
初始状态:
移入-归约过程:
· 语法分析器将零个或多个输入符号转移到栈顶上,直到它可以对栈顶的一个文法符号串𝛽进行归约为止
· 将𝛽归约为某个产生式的头
语法分析器重复上述循环,直到检测到错误或栈包含开始符号且输入为空
*在移入-归约解析过程中,句柄最终总是出现在栈的顶部
简单LR
LR(k)语法分析器:最流行的自底向上的语法分析器类型
· L: 从左到右扫描输入
· R: 反向构造最右推导
· k: 在做出解析决策时使用k个前瞻性输入符号
LR(0)和LR(1)语法分析器具有实际意义
当𝑘 ≥ 2时,语法分析器变得太复杂,无法构建(解析表太大,无法管理)
LR语法分析器的优势
· 表驱动(类似于非递归LL语法分析器)、强大
· 尽管手工构建LR语法分析器工作量太大,但也有一些语法分析器生成器可以自动构建语法分析表
· 相比之下,LL语法分析器往往更容易手工编写,但功能较弱(处理的语法较少)
· LR语法分析技术是已知的最通用的非回溯移入-归约语法分析方法
· LR语法分析器可以被构造为识别几乎所有可以为其编写CFG的编程语言结构
· LR语法比LL语法可以描述更多的语言
· 回想文法成为LL(1)的严格条件
LR(0) Items (LR(0)项)
一个LR语法分析器通过维护一些状态来跟踪在语法分析中所处的位置,从而来做出移入-归约的决策。
LR(0)项(简称item)是产生式再加上一个位于它的体中某处的点,表示在语法分析过程中的给定点上,我们已经看到了一个产生式的哪些部分。
𝐴 →} 𝑋𝑌𝑍 𝐴 → 𝑋 } 𝑌𝑍 𝐴 → 𝑋𝑌 } 𝑍 𝐴 → 𝑋𝑌𝑍 }
𝐴 → 𝑋 } 𝑌𝑍: 我们刚刚在输入中看到了一个可以由X推导得到的字符串,我们希望接下来看到一个能从YZ推导得到的字符串
状态:LR(0)项集
产生式𝐴 → 𝜖 仅生成一个item 𝐴 → ·
规范LR(0)项集族
LR(0)项集合的一个集合,称为规范LR(0)项集族, 为构建用于做出语法分析决定的DFA提供了基础
为了构造文法的LR(0)项集规范族,我们需要定义:
· 增广文法
· 两个函数:(1)项集闭包的CLOSURE 和(2)GOTO
增广文法
增广一个以S为开始符号的文法G:
· 引入一个新开始符号S‘代替S
· 增加产生式S‘ -> S
明显地𝐿(𝐺)=𝐿(𝐺’)
优点:通过增广,只有当语法分析器使用𝑆’ → 𝑆进行归约时输入符号串被接受。否则,输入符号串可能在多处被接受,因为可能存在多个𝑆-产生式
项集闭包
如果𝐼 是文法𝐺的一组项集, 那么CLOSURE(𝐼)就是按照下面两条规则构造的项集:
- 一开始,将𝐼中的各个项加入到CLOSURE(𝐼)
- 如果𝐴 → 𝛼 · 𝐵𝛽在CLOSURE(𝐼)中,𝐵 → 𝛾是一个产生式,并且𝐵 → ·𝛾不在CLOSURE(𝐼)中,那么将𝐵 → ·𝛾加入CLOSURE(𝐼)中。不断应用这条规则,直到没有新项可以加入到
直观地讲:𝐴 → 𝛼 · 𝐵𝛽 表示我们希望看到从一个能够从𝐵𝛽推导得到的子串。这个子串的某个前缀可以从B推导得到。因此,我们将所有𝐵-产生式加入到项集。
GOTO函数
𝐆𝐎𝐓𝐎(𝑰, 𝑿) 其中𝑰是一个项集而𝑿是一个文法符号,被定义为𝑰中所有形如的项所对应的项的集合的闭包。
LR(0)自动机
“简单LR语法分析技术”(即SLR分析技术)的中心思想是根据文法构造出LR(0)自动机。
· 这个自动机的状态是规范LR(0)项集族
· 它的转换由GOTO函数给出
· 开始状态是CLOSURE({𝑆’ →· 𝑆})
LR(0)自动机的使用
帮助做出移入-归约决定:
· 假设文法符号𝛾 使自动机从开始状态0运行到某个状态𝑗
· 如果下一个输入符号为𝑎且状态𝑗有一个在𝑎上的转换,那就移入𝑎
· 否则,归约;状态𝑗的项将会告诉我们使用哪个产生式进行归约
栈只保存状态,文法符号可以从相应状态中获取
LR语法分析器结构
LR语法分析器由一个输入、一个输出、一个栈、一个驱动程序和一个语法分析表(ACTION+GOTO)组成
所有LR语法分析器的驱动程序都是相同的;只有语法分析表随语法分析器的不同而变化
栈保存一个状态序列
在SLR中,栈保存来自LR(0)自动机的状态
语法分析器根据(1)栈顶部的状态和(2)从输入缓冲区读取的终结符来决定下一个动作
LR语法分析表:ACTION + GOTO
ACTION函数接受两个参数:(1)状态𝑖 和(2)终结符𝑎 (或$)
ACTION[𝒊, 𝒂] 可以具有以下四种形式的值之一:
· 移入𝒋: 其中𝑗是一个状态,把输入符号𝑎移入栈中,但使用状态𝑗 代表𝑎
· 归约𝑨 →𝛽: 将栈顶的𝛽归约为产生式头A
· 接受:语法分析器接受输入并完成语法分析过程
· 报错:存在语法错误
将定义在项集上的GOTO函数扩展为定义在状态集上的函数:如果GOTO(𝐼𝑖, 𝐴) = 𝐼𝑗,那么GOTO也把状态𝑖和一个非终结符A映射到状态𝑗
LR语法分析器的态势
“态势”是表示语法分析器完整状态的符号。态势是一个形如:(𝑠0𝑠1 … 𝑠𝑚, 𝑎i𝑎i+1 … 𝑎𝑛$)的对
第一个分量是栈中的内容,第二个分量是余下的输入。
根据结构,每个状态(除𝑠0)对应于一组项和文法符号(导致状态转换的符号,即传入边上的符号)
· 假设𝑋i是状态𝑠i的文法符号
· 那么𝑋0𝑋1 … 𝑋𝑚𝑎i𝑎i+1 … 𝑎𝑛是最右句型(假设没有错误)
构造SLR语法分析表
SLR语法分析表𝐺以LR(0)项和LR(0)自动机为基础。
- 构造增广文法G‘的规范LR(0)项集族{𝐼0, 𝐼1, … , 𝐼𝑛}
- 根据𝐼i构造得到状态i,状态i的语法分析动作按照下面的方法决定:
· 如果[𝐴 → 𝛼 · 𝑎𝛽]在𝐼𝑖中并且GOTO [𝐼𝑖, 𝑎 ]= 𝐼j,那么将ACTION[ 𝑖, 𝑎]设置为“移入j”
· 如果[𝐴 → 𝛼·]在𝐼𝑖中,那么对于𝐅𝐎𝐋𝐋𝐎𝐖(𝑨)中的所有𝑎,将设置ACTION[ 𝑖, 𝑎]为“归约𝐴 → 𝛼”。这里𝐴不等于S’
· 如果[𝑆’ → 𝑆·]在𝐼𝑖中,那么将设置ACTION[𝑖, $]为“接受” - 状态i对于各个非终结符号A的转换使用下面的规则构造得到:如果GOTO [𝐼i, 𝐴]= 𝐼𝑗,那么GOTO[𝑖, 𝐴]= 𝑗
- 规则2、3没有定义的所有条目都设置为“报错”
- 语法分析器的初始状态就是根据[𝑆′ → · 𝑆]所在项集构造得到的状态
如果在语法分析构造过程中没有冲突(即,一个表项的多个条目),则语法为SLR(1)
在SLR中,状态𝑖 要求归约𝐴 → 𝛼,如果项集$𝐼_𝑖$包含项[𝐴 → 𝛼 · ] ,同时输入符号𝑎 在FOLLOW(𝐴)中
在某些情况下,归约后𝛽𝛼 在栈顶上会变成𝛽𝐴, 后面跟着的不是𝑎的任何最右句型
规范LR
规范LR(1)项
在状态中携带更多信息以排除一些无效的归约(通过分裂LR(0)状态)
LR(1)项的一般形式:[𝐴 → 𝛼 · 𝛽, 𝑎]
· 𝐴 → 𝛼𝛽是一个产生式,𝑎是一个终结符或右端结束标记
· 1指的是第二个分量𝑎的长度,第二个分量𝑎叫做向前看字符
· 当𝛽不为空时,向前看字符没有任何作用因为它决定是否归约
· 一个形如[𝐴 → 𝛼· , 𝑎]的项只有在下一个输入符号等于𝑎时,才会按照𝐴 → 𝛼进行归约。这样的𝑎的集合总是的FOLLOW(𝐴)子集
𝐴 → 𝛼𝛽 是一个生产和𝑎 是终端还是$“1”是指第二个组成部分的长度:展望(向前看字符)*如果𝛽 不是𝜖 因为它只帮助确定是否减少(𝑎 将在状态转换期间继承)表单中的一项𝐴 → 𝛼· , 𝑎要求减少𝐴 → 𝛼 仅当下一个输入符号𝑎 (𝑎’s是FOLLOW的子集(𝐴))*:LR(0)项没有先行符号,因此它们被称为LR(0
构造LR(1)项集族本质上与构造规范LR(0)项集族相同。唯一的区别在于CLOSURE和GOTO函数。
构造LR(1)项集族本质上与构造规范LR(0)项集族相同。唯一的区别在于CLOSURE和GOTO函数。
向前看符号从现有项传递到新项
构造规范LR(1)语法分析表
- 构造增广文法G‘的规范LR(1)项集族{𝐼0, 𝐼1, … , 𝐼𝑛}
- 根据𝐼i构造得到状态i,状态i的语法分析动作按照下面的方法决定:
· 如果[𝐴 → 𝛼 · 𝑎𝛽, 𝑏 ]在𝐼𝑖中并且GOTO [𝐼𝑖, 𝑎 ]= 𝐼j,那么将ACTION[ 𝑖, 𝑎]设置为“移入j”
· 如果[𝐴 → 𝛼·, 𝑎 ]在𝐼𝑖中,设置ACTION[ 𝑖, 𝑎]为“归约𝐴 → 𝛼”。这里𝐴不等于S’
· 如果[𝑆’ → 𝑆·, $ ]在𝐼𝑖中,那么将设置ACTION[𝑖, $]为“接受”
如果以上规则导致任何冲突的动作,我们就说这个文法不是LR(1)的。 - 状态i对于各个非终结符号A的转换使用下面的规则构造得到:如果GOTO [𝐼i, 𝐴]= 𝐼𝑗,那么GOTO[𝑖, 𝐴]= 𝑗
- 规则2、3没有定义的所有条目都设置为“报错”
- 语法分析器的初始状态就是根据[𝑆′ → · 𝑆, $]所在项集构造得到的状态
Lookahead LR (LALR)
SLR(1)的功能不足以处理大量语法(回想一下以前的明确语法)
LR(1)在语法分析表中有一组庞大的状态(状态过于细粒度)
LALR(1)在实践中经常使用
· 在项中保留向前看符号
· 它的状态数与SLR(1)的状态数相同
· 可以处理现代程序设计语言中最常见的句法结构
寻找具有相同核心的LR(1)项集
LR(1)项集的核心是第一个分量的集合
· 𝐼4和𝐼7的核心是{𝐶 → 𝑑 ·}
· 𝐼3和𝐼6的核心是{𝐶 → 𝑐·𝐶,𝐶 → ·𝑐𝐶,𝐶 → ·𝑑}
一般而言,一个核心就是LR(0)项集
我们可以将具有共同核心的LR(1)项集合并为一组项目
由于GOTO的核心(𝐼, 𝑋) 仅取决于𝐼, 合并项集的GOTO目标也具有相同的核心,因此可以合并
状态合并引发的冲突
合并LR(1)语法分析表中的状态可能会导致冲突
合并不会导致移入/归约冲突
· 假设合并后在向前看符号𝑎上存在移入/归约冲突
· 有一个项[𝐴 → 𝛼·, 𝑎] 要求归约𝐴 → 𝛼
· 有其他项[𝐵 → 𝛽· 𝑎𝛾, ?]要求移入
· 由于要合并的集合的核心是相同的,因此合并前必须有一个集合同时包含[𝐴 → 𝛼· , 𝑎] 以及[𝐵 → 𝛽· 𝑎𝛾, ?]
· 那么根据LR(1)语法分析表构造算法,在合并之前,已经在𝑎上存在移入/归约冲突 。该文法不是LR(1)。
合并状态可能导致归约/归约冲突
构造LR(1)项集族$𝐶 = {𝐼_0,𝐼_1,𝐼_𝑛}$
对于LR(1)项集中的每个核心,找出所有具有这个核心的项集,并将这些项集替换为它们的并集
令$𝐶’ = {J_0,J_1,J_𝑛}$是合并后得到的项集族。
· 状态$𝑖$的语法分析动作是按照LR(1)语法分析表构造算法中的方法根据$𝐽_i$构造得到的
· 如果存在一个分析动作冲突,这个算法就不能生成语法分析器,这个文法不是LALR(1)的
GOTO表构造方法如下:
· 如果𝐽是一个或多个LR(1)项集的并集。也就是说 𝐽 = 𝐼1 𝖴 𝐼2 𝖴 ⋯ 𝖴 𝐼𝑘,那么GOTO(𝐼1, 𝑋), GOTO(𝐼2, 𝑋), …, GOTO(𝐼𝑘, 𝑋)的核心是相同的,因为𝐼1, 𝐼2, … , 𝐼𝑘具有相同的核心
· 令𝐾是所有和GOTO(𝐼1, 𝑋)具有相同核心的项集的并集
· 那么GOTO(𝐽, 𝑋)= 𝐾
错误恢复
LR语法分析中的错误恢复
LR语法分析器应该能够处理错误:
· 报告错误的精确位置
· 从错误中恢复并继续分析
两种典型的错误
· 恐慌模式
· 短语层次的恢复
恐慌模式
基本思想:丢弃零个或多个输入符号,直到同步词法单元已找到
原理:
· 语法分析器总是查找可以从非终结符𝐴推导的输入的前缀
· 当出现错误时,意味着无法找到这样的前缀
· 如果错误仅发生在与𝐴相关的部分, 我们可以通过寻找一个可以合法跟随的符号来跳过这一部分
· 示例:如果𝐴 是𝑠𝑡𝑚𝑡, 则同步词法单元可以是分号
短语层次的恢复
基本思路:
· 检查语法分析表中的每个错误条目,并确定最有可能导致错误的程序员错误
· 修改栈顶部或第一个输入符号,并向程序员发出消息
短语层次的恢复示例:
· 删除右侧的)
· 提示“不匹配的右括号”。
语法分析器生成工具
本节将介绍如何使用语法分析器生成工具来帮助构造一个编译器的前端,我们将使用LALR语法分析生成工具Yacc作为讨论的基础。Yacc,又一个编译器的编译器
Yacc在UNIX系统中是以命令的方式出现的,它已经用于实现多个编译器产品。Bison 是GNU项目的一部分,是对Yacc的扩展和改进。
声明
· 通常的C声明
· 对词法单元的声明
翻译规则
· 翻译规则 = 产生式 + 语义动作
辅助性C语言例程
· 将会被直接拷贝至y.tab.c
· 可以在语义动作中调用
· 必须提供yylex()这一词法分析器,它将返回一个由词法单元和相关属性组成的词法单元
· 可以添加错误恢复例程等其他过程
翻译规则
第一个产生式头符号被视为开始符号
一个语义动作是一个C语句的序列
· $$表示和相应产生时头部的非终结符关联的属性值
· $i表示和相应产生式体中第i个文法符号关联的属性值
当我们按照一个产生式归约时就会执行盒盖产生式相关联的语义动作
· 我们通常根据$i的值来计算$$的值
Yacc的冲突解决
默认策略:
· 移入/归约冲突:始终移入
· 归约/归约冲突:归约第一个列出的产生式
指定终结符的优先级和结合性:
· 结核性:%left、%right、%nonassoc
· 移入𝒂/归约𝑨 → 𝑎 冲突:比较的优先级𝑎 和𝐴 →𝛼 (优先级不够时使用结合性)
· 终结符的声明顺序决定了它们的优先级
· 一个产生式的优先级等于它最右边终结符的优先级。也可以使用%prec
Yacc的错误恢复
在Yacc中,错误恢复使用一种错误产生式的形式:
· 一般形式:𝐴 → 𝐞𝐫𝐫𝐨𝐫 𝛼
· 用户可以决定哪些非终结符(例如,生成表达式、语句、块等的非终结符)将具有错误产生式
错误示例:𝒔𝒕𝒎𝒕 → 𝐞𝐫𝐫𝐨𝐫 ;
· 该错误产生式规定当语法分析器遇到错误时,它要跳到下一个分号之后,并假设已经找到一条语句
· 将调用错误产生式的语义动作不需要处理输入,只需生成诊断消息
Chapter 4: Syntax-Directed Translation
语法制导的翻译
• 读取源程序的输入字符,将其归类为词素,并生成词素序列
• 必要时将词目添加到符号表中
• 删除注释和空白(空格、换行符、制表符等)
• 将错误信息与行号关联起来(跟踪换行符)
语法制导定义(SDD)是一种无上下文语法,同时包含属性和规则。
一组属性(attributes)与每个语法符号相关联*。
可以是任何属性,例如表达式的数据类型,# 生成代码中的指令
语义规则(semantic rule)与语法生成相关联,描述如何计算属性
属性代码表示结构体的后缀符号
|| 是字符串连接操作符
合成属性
如果一个属性在解析树节点 N 上的值仅由 N 的子节点和 N 本身的属性值决定,则称该属性为合成属性;
SDD 不指定解析树上属性的计算顺序
任何顺序,只要能在依赖的所有其他属性之后计算一个属性就可以了合成属性有一个很好的特性,
即它们可以在解析树的一次自下而上的遍历中进行评估(通常不需要显式创建解析树)。
继承属性
继承属性在解析树节点上的值由该节点本身、其父节点和解析树中同级节点的属性值决定
回答:继承属性在处理与上下文相关的问题时仍然是非常有用的。它为我们提供了一种在语法树中考虑外部信息的方法,从而使得我们可以更为精确和灵活地描述语法制导定义的属性
给定解析树节点 $N,M_1,M_2,M_3,…,M_k,$如果 N 的属性 a 定义为 $N.a = f(M_1,a_1,M_2,a_2,…,M_k,a_k)$,那么为了计算 N.a,我们必须先计算 $M_1. a_1$。
依赖图 (依赖图) 是确定评估顺序的有用工具
描述特定解析树中属性实例之间的信息流
为属性实例之间的部分顺序建模
从一个属性实例$(a_1)$到另一个属性实例$(a_2)$的边表示计算 $a_2$ 的值需要 $a_1$ 的值。
如果依赖关系图中存在循环,我们就无法找到计算所有属性实例值的顺序ε
S 属性定义
如果每个属性都是合成的,那么语法制导定义就是 S 属性的
直观地说,任何解析树的依赖关系图中都不可能存在循环,因为边总是从子节点到父节点,而不是相反。
当 SDD 具有 S 属性时,我们可以按照解析树节点的任何自下而上的顺序评估其属性。
例如,解析树的后序遍历(postorder traversal)
S 属性定义可以在自下而上的解析过程中轻松实现(相当于后序遍历)
L 属性定义
如果对于每个产品 $A → X_1X_2…X_n$,对于每个 J = 1 … n,$x_j$ 的每个继承属性仅取决于以下属性,则 SDD 是 L 属性 SDD:
$x_1,…x_{j-1}$ 的属性(合成的或继承的),
或 A 的继承属性
依赖关系图的边可以从左到右(对于解析树而言),但不能从右到左(因此称为 “L-属性”)。
L 属性定义的属性评估
输入: 解析树 T 中的节点 n
输出: 以 n 为根的子树属性的评估顺序
程序 depth_first(n)*
开始
对于 n 的每个子节点 m,从左到右依次执行 开始
评估 m 的继承属性;
depth_first(m); // 这里将评估 m 的合成属性
结束
评估 n 的合成属性;
保证:在评估节点的继承属性时,已评估了其左侧节点的属性
end
构建语法树
抽象语法树
每个内部节点 N 代表一个结构体(对应一个运算符)
N 的子节点代表 N 所代表结构的有意义成分(相当于操作数)
语法树与解析树
在语法树中,内部节点代表编程结构,而在解析树中,内部节点代表非终结符*。
解析树也称为具体语法树,其底层语法称为语言的具体语法
为简单表达式构建语法树的 S 属性 SDD
语法树的每个节点都是一个对象,其中有一个字段 op(代表节点的标签)和一些附加字段
叶节点:一个包含词法值的附加字段
内部节点:额外的字段数量等于子节点的数量
计算类型的结构
• 正则语言(regular language)是一种可由 regexp
• 如果两个 regexps r 和 s 表示相同的语言,那么它们是等价的,写成 r = s
合成属性:这种属性通常用于将信息从叶子节点向上传递到父节点。在这里,合成属性t代表一个类型,这意味着某个节点(可能是一个变量或表达式)的类型可以通过计算其子节点的属性来确定,并将这个类型作为其自己的t属性。
继承属性:这种属性是从父节点传递给子节点的。在这个描述中,继承属性t在解析树中向下传递一个基本类型。这通常意味着上层节点(例如,声明或类型定义的上下文)已经确定了某种基本类型,这个类型需要向下传递给子节点,以确保子节点可以根据这个类型进行相应的操作或检查。
Syntax-Directed Translation Schemes
SDD 告诉我们在翻译中要做什么(高级规范),但不告诉我们如何做
语法制导的翻译方案(SDT’s,Syntax-directed translation schemes)规定了如何进行翻译的更多细节。
SDT 是一种无上下文语法,其语义动作(程序片段)嵌入在生产体中 :
与 SDD 的语义规则不同
语义动作可以出现在制作体的任何地方
任何 SDT 都可以通过以下方式实现:
首先构建一棵解析树
将语义操作视为 “虚拟 “解析树节点
执行从左到右的深度优先(即预排序)树遍历,并在访问相应节点时触发操作
SDD(Syntax Directed Definition):
SDD定义了与语法产生式关联的属性和规则。它为每个语法产生式指定一个或多个属性计算或语义动作。
SDD关注于如何为语法树中的节点计算属性值,但不一定涉及产生中间代码或目标代码的具体操作。
它可以有合成属性和继承属性,因此可以描述为S属性的(只有合成属性)或L属性的(允许继承属性但有限制)。
SDT(Syntax Directed Translation):
SDT是SDD的一个特例,它专门用于生成中间代码或目标代码。换句话说,SDT的目的是翻译,它定义了与语法产生式关联的动作,这些动作通常在解析时执行。
当解析器在处理产生式时,与该产生式关联的SDT动作被执行,从而生成代码或进行其他翻译工作。
动作可以嵌入到产生式中,例如,在YACC或Bison这样的工具中,可以直接在语法规则中插入C代码作为动作。
总结差异:
SDD更为通用,关注于为语法树的节点计算属性。这些属性可以用于多种目的,如类型检查、变量绑定等。
SDT特化于翻译任务,即将源代码转换为中间代码或目标代码。它通常涉及在解析过程中执行特定的动作。
尽管有这些区别,但在实际应用中,SDD和SDT的界限可能会模糊,因为编译器的语义分析和翻译阶段通常是交织在一起的
$$
B->X{a}Y
$$
动作 a 应在我们识别完 X(如果 X 是终端)或由 X 派生的所有终端(如果 X 是非终端)后执行
如果解析是自下而上的,那么一旦 X 出现在解析栈顶端,我们就执行操作 a
如果解析是自上而下的,我们在尝试扩展 Y(如果 Y 是非终端)或检查输入中的 Y(如果 Y 是终端)之前执行操作 a
底层语法是LR,而SDD是S属性的:
LR语法:这是一种可以用自底向上的方式进行解析的语法。LR解析器从左到右读取输入,但决策是基于右侧的上下文进行的。它使用一个堆栈来存储已经读取的符号,并在适当的时候进行规约。
S属性的SDD:这意味着所有属性都是合成属性,它们只从子节点传递给父节点,没有从父节点传递给子节点的继承属性。这对于自底向上的LR解析是非常合适的,因为我们从叶子节点开始构建并向上移动,因此只需要合成属性即可。
底层语法是LL,而SDD是L属性的:
LL语法:这是一种可以用自顶向下的方式进行解析的语法。LL解析器从左到右读取输入,并基于左侧的上下文来进行决策。它通常使用递归下降的方法,直接从起始符号开始,并尝试应用各种产生式。
如果 SDD 的语法是 LR,而且 SDD 是 S 属性的,那么我们就可以构造一个后缀 SDT(后缀 SDT),在自下而上的解析中实现 SDD 语义动作总是出现在制作的末尾(因此称为 “后缀”)。
SDT’s for L-Attributed SDD’s
如果基础语法是 LL,那么 L 归因 SDD 可以在自上而下的解析过程中实现。
将 L 属性 SDD 转化为 SDT 的方法是将语义动作放在相关语篇 A → X1X2…Xn 的适当位置上。
将计算非终端 Xi 的继承属性的动作紧接在生产体中 Xi 的前面
将为语篇头部计算合成属性的操作放在语篇主体的末尾
构建整个词法分析器
• 策略 1:依次尝试每个标记的过渡图
fail() 重置指针并开始下一个图表
• 策略 2:并行运行过渡图
需要解决一个图找到一个词素,而其他图仍能处理输入的情况。
▪ 解决方法:取输入中与任何模式匹配的最长前缀
• 策略 3:将所有过渡图合并为一张图(首选)
允许过渡图读取输入,直到没有可能的下一个状态为止
取与任何模式匹配的最长词素
语义操作:
a) L1 = new();L2 = new();
b) C.false = S.next; C.true = L2;
c) S1.next = L1;
d) S.code = ⋯ ;
根据动作位置规则,
b) 应放在制作体之前,c) 应放在制作体之前,d) 应放在制作体末尾
a) 可以放在开头;没有限制条件
Implementing L-Attributed SDD’s
许多翻译应用都可以使用 L 归因 SDD 来解决。如下所示,我们可以扩展递归-后裔解析器来实现 L 归因 SDD:
递归-迭代解析器为每个非终端 A 都有一个函数 A
使用函数 A 的参数传递 A 的继承属性
当函数 A 完成时,返回 A 的合成属性
通过上述扩展,在函数 A 的主体中,我们需要同时解析和处理属性
Chapter 5: Intermediate-Code Generation
中间表示法
编译器的前端分析源程序并创建中间表示(IR,intermediate representation),后端据此生成目标代码。
理想情况下,源语言的细节仅限于前端,目标机的细节仅限于后端
编译器可构建 IR 序列
语法树等高级 IR 接近源语言。它们描述了源程序的结构,适用于静态类型检查等任务
低级 IR 接近目标机器,适用于寄存器分配和指令选择等与机器相关的任务。
三地址代码可以是高级或低级的,取决于运算符的选择
有趣的事实:C 经常被用作中间形式。第一个 C++ 编译器的前端生成 C,后端是 C 编译器
DAG’s for Expressions
在语法树中,一个普通子表达式的语法树将按该子表达式出现的次数复制
Example: $𝑎+𝑎∗(𝑏−𝑐)+(𝑏−c)∗𝑑$会重复两次,而$(b-c)$也重复了两次
有向无环图 (DAG, 有向无环图) 识别共同的子表达式,并简洁地表示表达式
蓝圈节点有两个父节点
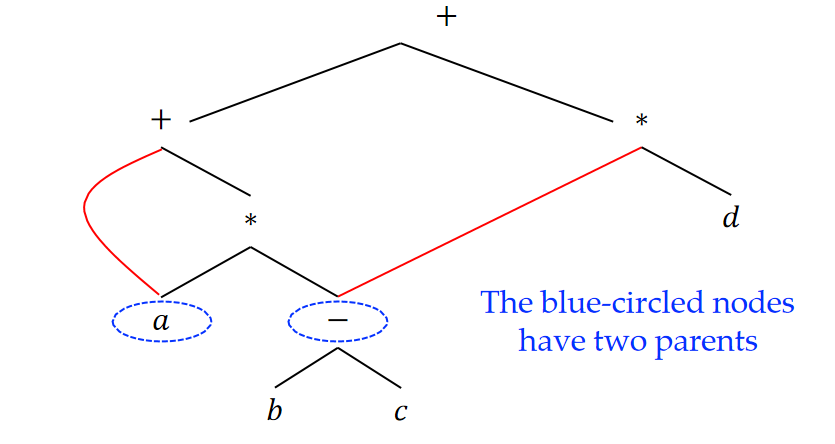
DAG 可以用构造语法树的 SDD 来构造
区别:在构建 DAG 时,只有当且仅当没有现存的相同节点时,才会创建新节点
Three-Address Code (三地址代码)
在三地址代码中,指令右侧最多只有一个运算符
指令的形式通常是 $𝑥 = 𝑦\ 𝑜𝑝\ 𝑧$
运算符(或地址)可以是:
源程序中的名称
常量:编译器必须处理多种类型的常量
编译器生成的临时名称
结构
赋值指令:
𝑥 = 𝑦 op 𝑧,其中 op 是二进制算术/逻辑运算
𝑥= op 𝑦,其中 op 是一元运算
复制指令: 𝑥 = 𝑦
无条件跳转指令:goto 𝐿,其中 𝐿 是跳转目标的标记
有条件跳转指令:
if 𝑥 goto 𝐿
if Flase 𝑥 goto 𝐿
if 𝑥 relop 𝑦 goto 𝐿
程序调用和返回:
param 𝑥1
…
param 𝑥𝑛
call 𝑝, 𝑛 (procedure call)
y = call p, n (function call)
return y
索引复制指令: 𝑥 = 𝑦[𝑖] 𝑥[𝑖] = 𝑦
这里,𝑦[𝑖] 表示位置 𝑖 存储单元中超出位置 𝑦 的值。这里,𝑦[𝑖] 表示位置 𝑖存储单元中超出位置 𝑦 的值。
地址和指针赋值指令:
𝑥 = &𝑦 ,𝑥 =∗ 𝑦, ∗ 𝑥 = 𝑦
对三地址指令的描述说明了每种指令的组成部分,但没有说明指令的表示方法。
在编译器中,这些指令可以作为对象/记录来实现,并为运算符和操作数设置字段
三种典型的表示法:四元式表示方法
三元式表示方法
间接三元式表示方法
Quadruples (四元式)
一个四元组(或 “四元组”)有四个字段
一般形式: op arg1 arg2 result
op 包含运算符的内部代码
arg1、arg2、result 是地址(操作数)
一元运算符(如 x = 减 y 或 x = y)不使用 arg2
参数运算符既不使用 arg2 也不使用 result
条件/非条件跳转将目标标签放在 result 中
Triples (三元式)
三元组只有三个字段:操作、参数 1、参数 2。
我们用操作 x 操作 y 的位置来表示操作结果,而无需生成临时名称(这是对四元组的优化)
Indirect Triples (间接三元式)
间接三元组由一个指向三元组的指针列表(下面的指令数组)
优化可以通过重新排序指令列表来移动指令(无需修改三元组)
交换后,列表中的第一条和第二条指令仍然指向正确的指令
静态单赋值形式静态单赋值形式(SSA,Static Single-Assignment ForStatic single-assignment form)是一种 IR,有助于某些代码优化。
在 SSA 中,每个名称只接受一次赋值
SSA 使用一种称为 𝜙 函数的符号惯例来合并 x 的两个定义
Types and Type Checking
数据类型或简单的类型告诉编译器或解释器程序员打算如何使用数据
类型信息的作用
查找源代码中的错误
在运行时确定名称所需的存储空间
计算数组元素的地址
插入类型转换
选择算术运算符的正确版本(如 fadd、iadd)
类型检查(类型检查) 使用逻辑规则确保操作数的类型与运算符所期望的类型匹配
Type Expressions (类型表达式)
类型具有结构,可以用类型表达式来表示
类型表达式要么是基本类型,要么是通过对类型表达式应用类型构造算子而形成
array(2, array (3, integer ))是 int[2][3] 的类型表达式
array 是一个类型构造函数,有两个参数:一个数字,一个类型表达式
Name Equivalence (名等价)
将命名的类型视为基本类型;类型表达式中的名称不会被其定义的类型表达式所替换
当且仅当两个类型表达式完全相同时,它们的名称才是等价的(由相同的语法树表示,具有相同的标签)
Structural Equivalence (结构等价)
对于已命名的类型,用其类型表达式替换类型名,并递归检查替换后的树
Declarations (类型的声明)
下面的语法涉及基本类型、数组类型和记录类型
非终端 𝐷生成声明序列
𝑇 生成基本类型、数组类型或记录类型,记录类型是记录字段的声明序列,由大括号包围
𝐵 生成基本类型之一:int 和 float
𝐶 生成一个或多个整数的序列,每个整数都由大括号包围
Storage Layout for Local Names (局部变量的存储布局)
根据名称的类型,我们可以决定运行时名称所需的内存量。运行时名称所需的内存量
类型的宽度(宽度): 该类型对象所需的 # 内存单位
对于长度不等的数据(如字符串),或在运行前无法确定大小的数据(如动态数组),我们只为数据指针预留固定的内存量。
对于函数的局部名称,我们总是分配连续的字节*。
对于每个这样的名称,我们可以在编译时计算出一个相对地址
类型信息和相对地址存储在符号表中
表达式的翻译
包含多个运算符的表达式:𝑎 + 𝑏 ∗ 𝑐
转换为多条指令,每条指令最多使用一个运算符𝑡1 = 𝑏 ∗ 𝑐,𝑡2 = 𝑎 + 𝑡1
数组引用𝐴[𝑖][𝑗] 将扩展为一系列三地址指令,用于计算引用的地址
 wechat
wechat- alipay





