
编译原理Lab2——了解词法分析器生成器Lex并进行使用
一、 实验内容
- 了解词法分析器生成器Lex并进行使用
- 学习Lex程序的结构
二、 实验过程
1.运行wc程序示例
(1)启动docker环境,进入实验目录
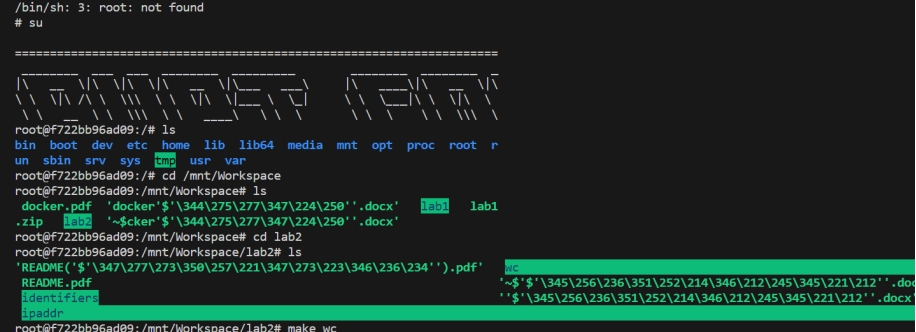
(2)运行wc目标,并和Linux自带wc命令进行比较

从以上结果可以看出,自主实现的wc命令比Linux分出的词更多。
(3)区别分析
在自主实现的wc语句中使用以下语句进行分词
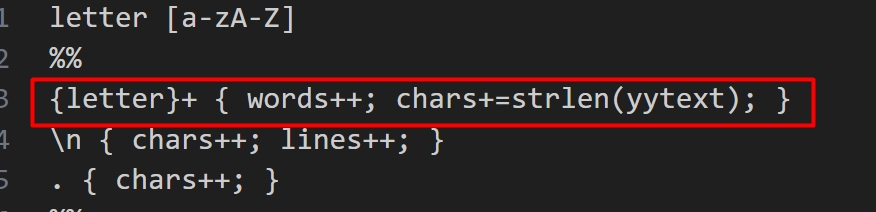
当 Lex 分析器遇到一个或多个字母字符(即一个单词)时,它会增加 words 变量的计数,并且使用 strlen(yytext) 来计算这个单词的长度,并将结果累加到 chars 变量上。这就是以字母字符为单词的语义划分方式,而不考虑单词之间的标点符号或空格。因此只有遇到完整单词之后就会计数器加一。
而在Linux的wc指令中通过以下代码进行单词计数:
1 | static void |
该代码中 count_words 函数使用一个有限状态自动机来处理文本字符,根据字符类型划分单词。当遇到空格字符(包括空格和制表符)时,它将从单词状态切换到空格状态,并递增单词计数。
因此二者分词方式上存在区别,统计词数也有所不同。
3.Flex标识符练习
(1)进入目录文件夹,执行操作指令

(2)观察执行结果
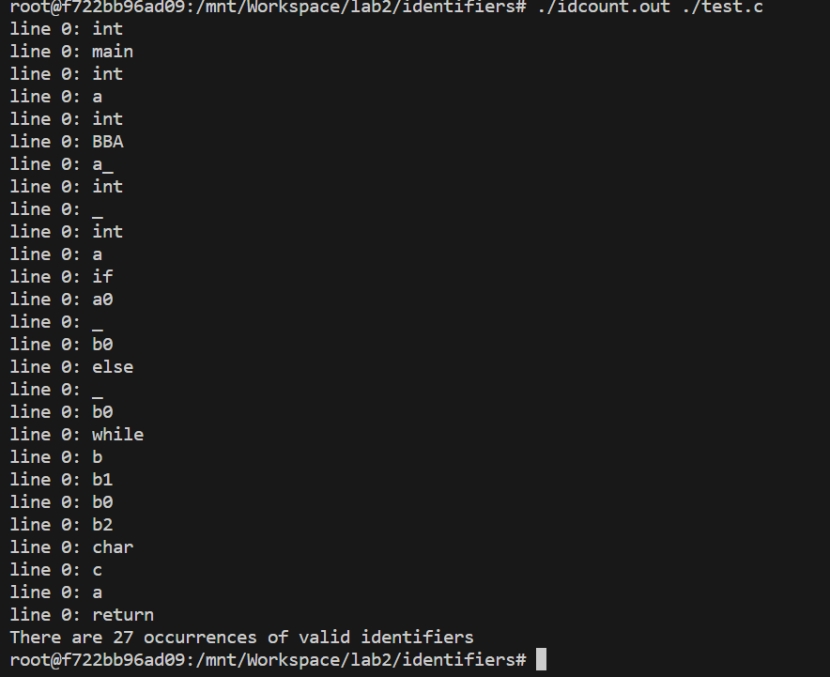
发现输出中的行号与令牌的行号不匹配
(3)查看源代码进行更改
检查发现在输出语句中调用的行号未使用递增,导致输出行号错误
1 | printf("line %d: %s\n", lines, yytext); |
对其进行更改从而实现行号的更新
1 | int identifier_line = 1; // 初始化为第一行 |
(4)更新后重新进行编译执行
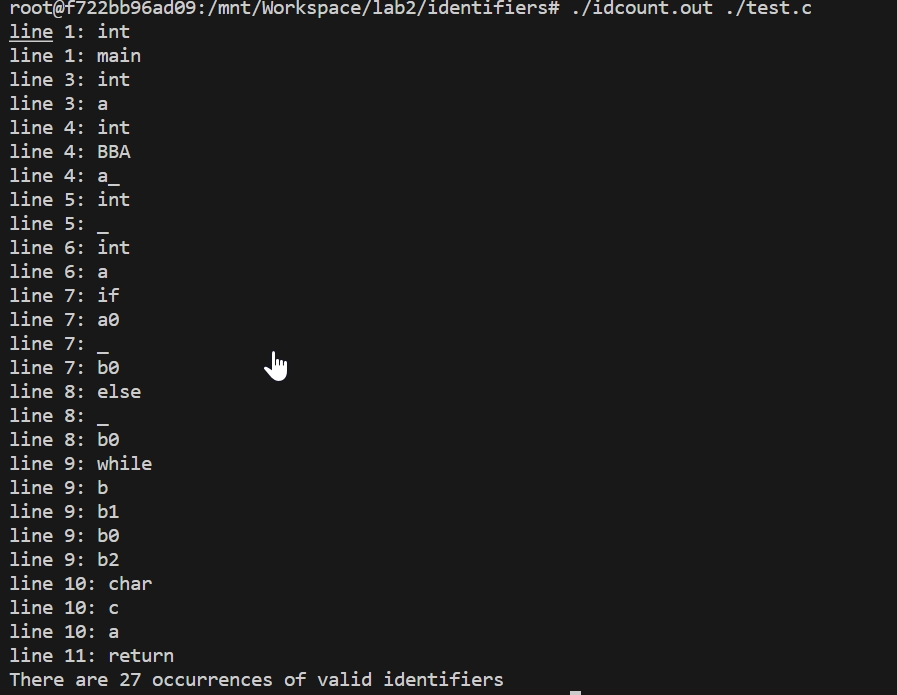
(5)关键代码分析
%{ … %} 部分:这部分包含了在词法分析器中使用的宏定义和全局变量的声明。
正则表达式定义:在 letter、letter_ 和 digit 部分定义了正则表达式片段,分别用于匹配字母、字母或下划线、和数字。
%% 部分:这是Lex规则的主体部分,其中定义了词法分析规则。
int main(int argc, char **argv) 函数:这是程序的入口点。代码能够识别文本文件中的标识符并输出它们的行号和文本。
4.ipaddr练习
(1)尝试直接输出,发现报错

(2)更改代码,编写正则表达式

(3)检查输出结果

三、 遇到困难和解决办法
- docker打开时出错,需要更改指令重新实现,具体如下
管理员身份打开命令行工具 netsh winsock reset
就可以重新打开docker,如果不成功,再重启电脑就好了。可以就不用重启了。
 wechat
wechat- alipay




