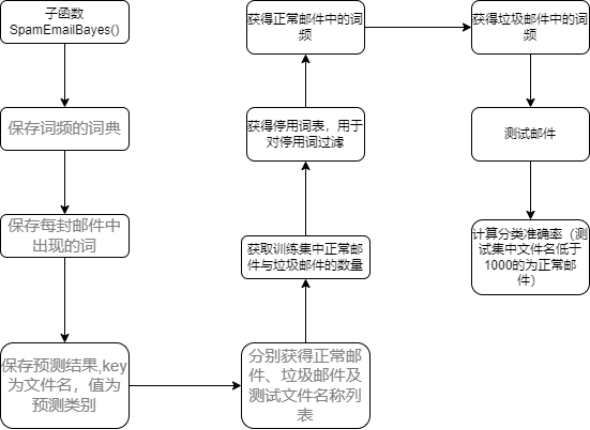
defgetTestWords(self, testDict, spamDict, normDict, normFilelen, spamFilelen): wordProbList = {} for word, num in testDict.items(): if word in spamDict.keys() and word in normDict.keys(): \# 该文件中包含词个数 pw_s = spamDict[word] / spamFilelen pw_n = normDict[word] / normFilelen ps_w = pw_s / (pw_s + pw_n) wordProbList.setdefault(word, ps_w) if word in spamDict.keys() and word notin normDict.keys(): pw_s = spamDict[word] / spamFilelen pw_n = 0.01 ps_w = pw_s / (pw_s + pw_n) wordProbList.setdefault(word, ps_w) if word notin spamDict.keys() and word in normDict.keys(): pw_s = 0.01 pw_n = normDict[word] / normFilelen ps_w = pw_s / (pw_s + pw_n) wordProbList.setdefault(word, ps_w) if word notin spamDict.keys() and word notin normDict.keys(): \# 若该词不在脏词词典中,概率设为0.4 wordProbList.setdefault(word, 0.4) sorted(wordProbList.items(), key=lambda d: d[1], reverse=True)[0:15] return (wordProbList)

 wechat
wechat



